To get to an operational control plane, we need to come to a state of declarative data pipeline orchestration that knows exactly about each data product and its metadata. Instead of siloed data with unbundling, we need to support the Modern Data Stack tools and orchestrate them in a unified way.
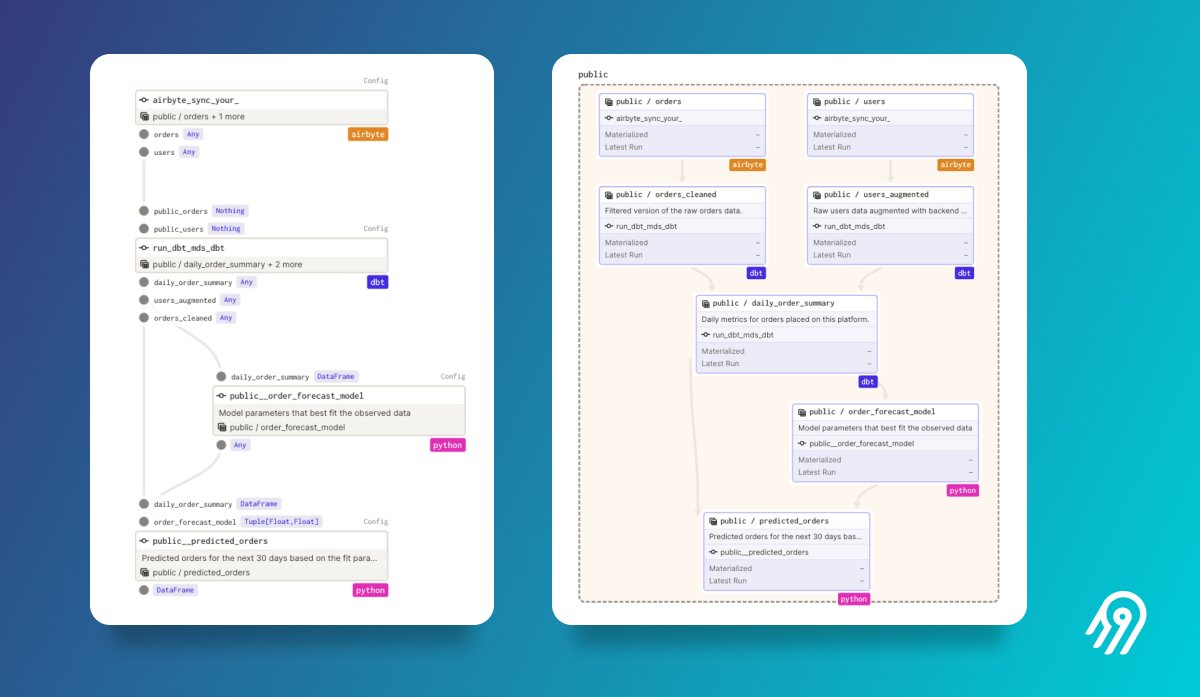
Let’s look at how a data-aware pipeline manifests in a real-live use case. Within Dagster, you see the non-data aware pipeline on the left vs. the data-aware data-asset driven pipeline on the right.
Normal data pipeline on the left, data product view on the right. Notice that from one block on the left, we get 2 Airbyte data assets and 3 dbt models on the right. Note: These two graphs co-exist and can be toggled.
On the right, you see the data products `orders, daily_order_summary, and predicted_orders` defined ahead of any run. No need to execute anything first. We want these artifacts to be available and programmatically define them.
One step more of a data-aware pipeline is integrating the MDS tools with metadata, such as the SQL statement out of the dbt model or the database schema from the dbt table, or information about an Airbyte sync. Below is the dbt example with Dagster.
Data-Aware pipeline with integrated Metadata from the Modern Data Stack tools
The Missing Data Mesh Layer: The Data Product Graph
To conclude this chapter, we can say that everything we talked about in this chapter will essentially lead to the Data Product Graph, which contains all relevant information for an Analyst or Business User to see the upstream dependency and core business logic. If you will, it bundles some of the modern data tools into a unified data product graph. It's a shift to a new way of organizing data and heterogeneous sources. To extend, it allows the user to self-serve as we once dreamt of in the Business Intelligence world.
Illustration of a Data Product Graph
ℹ️ According to the Data Mesh Paper: The most common failures of the past for building an intelligence platform are first-generation proprietary enterprise data warehouse and business intelligence solutions with lots of technical debt in unmaintainable ETL jobs and reports. And second-generation big data ecosystems with data lakes (swamps?) with long-running batch jobs operated by a central team specialized in data engineering. As I do not agree with everything said in the paper, I believe two of the reasons for the above failures are missing abstractions and tools that support the data products.
Next, let's look at modern open-source orchestrators and when to use them.
Modern Data Orchestrator Tools
As a modern Data Orchestrator, we call one with the above-mentioned higher-level abstractions, data assets, and additional data-aware features on top of task orchestration.
Where Do We Come From: The Evolution of Data Orchestration
Traditionally, orchestrators focused mainly on tasks and operations to reliable schedule and workflow computation in the correct sequence. The best example is the first orchestrator out there, cron. Opposite to crontabs, modern tools need to integrate with the Modern Data Stack.
To understand the complete picture, let’s explore where we came from before Airflow and other bespoken orchestrators these days.
In 1987, it started with the mother of all scheduling tools, (Vixie) cron
If you are curious and want to see the complete list of tools and frameworks, I suggest you check out the Awesome Pipeline List on GitHub.
💡 Besides the above open-sourced, we have closed-source, mostly low-code or no-code solutions involving scheduling, such as Databricks with the acquisitions of bamboolib, Ascent.io, Palantir Foundry, and many more.
Data Orchestration Platform: Unbundling vs. Bundling
Do we think of data orchestrators as data orchestration platforms that bundle different tools, or should they be unbundled? For example, in The Unbundling of Airflow, Gorkem explains the open-source ecosystem:
We have seen the same story over and over again. Products start small, in time, add adjacent verticals and functionality to their offerings, and become a platform. Once these platforms become big enough, people begin to figure out how to serve better-neglected verticals or abstract out functionality to break it down into purpose-built chunks, and the unbundling starts.
Furthermore, the Airflow DAG is being split from end-to-end data pipelines to ingestion tools (Airbyte, Fivetran, Meltano), transformational tools (dbt), reverse ETL tools (Census, Hightouch), and metrics layers (Transform), ML-focused systems (Continual), just to name a few. Dagster immediately stated a post about Rebundling the Data Platform slouching toward this “unbundled” world that moves from imperative tasks to declarative data assets. These can be seen as orchestrator platforms providing some of the data catalog and data lineage tool's responsibilities.
What Are Trendy Open-Source Data Pipeline Orchestration Tools
As we've laid out where we come from with orchestration and what the evolutions were, what is the current trend? Let's dig deeper into some data pipeline orchestrators that support that future. Also, let's see when you'd use each orchestrator.
The evolution shows that the most stable and widely used orchestrator is Apache Airflow. It’s the base of many prominent tech companies. As it was the first of its kind with Luigi and Oozie, it grew with some of the core philosophies built-in from the very beginning. One is a pure schedule, not knowledgeable about the inner life of a task. It wasn’t designed to interact with inputs and outputs of data (old XComs debate). In Airflow 2.0, the new feature TaskFlow provides a better developer experience to pass data from one task to another but still relies on XCom. When orchestrating data pipelines with Airflow is still recommended to use intermediary storage to pass data between different tasks. That’s why I call Airflow a simple orchestrator in this article, and we mainly focus on the “modern” data orchestrator such as Prefect vs Dagster.
I will leave Kedro aside as the momentum is on the other two, and it focuses mostly on data science. Temporal is another fascinating orchestrator. At Airbyte, we internally use the Temporal Java SDK to orchestrate ETL jobs. Temporal focuses on real-time application orchestration instead of heterogeneously complex cloud environments. As of today, Temporal lets you write workflows in Java, Go, TypeScript and PHP, and provides no Python support.
As seen in the abstraction chapter above, modern orchestrators already support vast abstractions: the two most prominent ones and some suggestions on when to use them below.
Prefect if you need a fast and dynamic modern orchestration with a straightforward way to scale out. They recently revamped the prefect core as Prefect 2.0 with a new second-generation orchestration engine called Orion. It has several abstractions that make it a swiss army knife for general task management.
Dagster when you foresee higher-level data engineering problems. Dagster has more abstractions as they grew from first principles with a holistic view in mind from the very beginning. They focus heavily on data integrity, testing, idempotency, data assets, etc.
📖 A good sense of what has changed between simple to modern orchestrators, you can find the difference in Dagster vs Airflow. 📖 A good read about how Prefect sees the History of Dataflow Automation.
💡 Interesting that dbt, as the mother of SQL transformation, also puts Python on their Roadmap (besides others such as their own Metrics Layer). Engaging discussions are ongoing about integrating with external tools such as Dagster vs Prefect.
Data Orchestration Examples
Here are some hands-on examples that help you get started with the world of data-aware orchestrators.
This Demo shows the Airbyte integration with dbt in one declarative data asset pipeline, including the rich metadata such as db-schema from Airbyte and other valuable metadata. Check out the Tutorial and Code on GitHub.
The same goes for integrating prefect, dbt, and Airbyte—the Demo on YouTube, a Tutorial, and the Code on GitHub.
Conclusion and Outlook
I hope you better understand the importance of focusing on the data products instead of data pipelines and why it is better to write declarative code so that data pipelines can update themselves when upstream data assets change. We also covered reasons for using abstractions in the complex big open-source data world and how to make pipelines more data-aware to align with the mission of the data mesh.
The next addition to your data stack could be integrating all this valuable metadata of data assets into a data catalog. If you like the Airbyte blog you can sign up for the Newsletter. In an upcoming article, I will discuss the Metrics Layer and demystify the hype around it.
If you have comments, critics, or other trends in the data orchestration world, join our Slack Community to network with 6000+ data engineers.
I am looking forward to debating it with you.
The data movement infrastructure for the modern data teams.
Simon is a Data Engineer and Technical Author at Airbyte. He is dedicated, empathetic, and entrepreneurial with 15+ years of experience in the data ecosystem. He enjoys maintaining awareness of new innovative and emerging open-source technologies.