

MySQL is an SQL (Structured Query Language)-based open-source database management system. An application with many uses, it offers a variety of products, from free MySQL downloads of the most recent iteration to support packages with full service support at the enterprise level. The MySQL server, while most often used as a web database, also supports e-commerce and data warehousing applications and more.
A communication solutions agency, Kafka is a cloud-based / on-prem distributed system offering social media services, public relations, and events. For event streaming, three main functionalities are available: the ability to (1) subscribe to (read) and publish (write) streams of events, (2) store streams of events indefinitely, durably, and reliably, and (3) process streams of events in either real-time or retrospectively. Kafka offers these capabilities in a secure, highly scalable, and elastic manner.
1. Open the Airbyte UI and navigate to the "Sources" tab.
2. Click on the "Add Source" button and select "MySQL" from the list of available sources.
3. Enter a name for your MySQL source and click on the "Next" button.
4. Enter the necessary credentials for your MySQL database, including the host, port, username, and password.
5. Select the database you want to connect to from the drop-down menu.
6. Choose the tables you want to replicate data from by selecting them from the list.
7. Click on the "Test" button to ensure that the connection is successful.
8. If the test is successful, click on the "Create" button to save your MySQL source configuration.
9. You can now use your MySQL connector to replicate data from your MySQL database to your destination of choice.
1. First, you need to have an Apache Kafka destination connector installed on your system. If you don't have it, you can download it from the Apache Kafka website.
2. Once you have the Apache Kafka destination connector installed, you need to create a new connection in Airbyte. To do this, go to the Connections tab and click on the "New Connection" button. 3. In the "New Connection" window, select "Apache Kafka" as the destination connector and enter the required connection details, such as the Kafka broker URL, topic name, and authentication credentials.
4. After entering the connection details, click on the "Test Connection" button to ensure that the connection is working properly.
5. If the connection test is successful, click on the "Save" button to save the connection.
6. Once the connection is saved, you can create a new pipeline in Airbyte and select the Apache Kafka destination connector as the destination for your data.
7. In the pipeline configuration, select the connection you created in step 3 as the destination connection.
8. Configure the pipeline to map the source data to the appropriate Kafka topic and fields.
9. Once the pipeline is configured, you can run it to start sending data to your Apache Kafka destination.
With Airbyte, creating data pipelines take minutes, and the data integration possibilities are endless. Airbyte supports the largest catalog of API tools, databases, and files, among other sources. Airbyte's connectors are open-source, so you can add any custom objects to the connector, or even build a new connector from scratch without any local dev environment or any data engineer within 10 minutes with the no-code connector builder.
We look forward to seeing you make use of it! We invite you to join the conversation on our community Slack Channel, or sign up for our newsletter. You should also check out other Airbyte tutorials, and Airbyte’s content hub!
What should you do next?
Hope you enjoyed the reading. Here are the 3 ways we can help you in your data journey:



Enterprise use cases often involve integrating data from various sources and analyzing logs and activity streams. For instance, if you are building an e-commerce application backed by a relational database, such as MySQL, you might need to combine incoming order data with other downstream data for operational analytics.
Relational databases maintain a transaction log that records every event in the database. An update, an insert, a delete — all go into the database's transaction log. Rather than moving all the order data in bulk, Change Data Capture (CDC) approaches are used, allowing you to stream every single event from the database as it occurs into a streaming platform like Apache Kafka.
By consuming the logs from MySQL CDC, data integration tools such as Airbyte can extract data changes at very low latency and deliver them seamlessly to Kafka, which serves as a central integration point for numerous downstream data feeds in and out.
This tutorial will explain how to sync data from a MySQL database to Kafka using CDC. The process is similar for all Airbyte database sources that support CDC, like Postgres and MSSQL.
What is Change Data Capture (CDC)?
Change Data Capture (CDC) is an efficient replication technology that allows row-level data changes at the source database to be quickly identified, captured, and delivered in real-time to the destination database store. With CDC in use, only the data that has changed — categorized by insert, update, and delete operations — since the last replication is transferred.
How does CDC work in MySQL?
MySQL contains an internal feature called binary log (binlog) that records all database operations, including DDL and changes to table data.
Even if activating binary logging in a MySQL server may have a minor impact on speed, having a binlog is helpful in data recovery and replication situations. The latter is particularly important in the context of this tutorial since it permits the implementation of ELT pipelines from MySQL, the binlog.
The infrastructure that continually monitors the binlog for activities committed to the source database is referred to as MySQL CDC. When the list of operations in the binlog is copied to the destination, the ELT's load (L) component is accomplished.
Pre-requisites
Here are the tools you’ll need to start replicating data from a MySQL database to Kafka.
- You’ll need to get Airbyte to do the data sync for you. In this tutorial, we run Airbyte in a docker container locally using the instructions in our documentation.
- You will need a MySQL instance to be used as your source for CDC. MySQL instances can be set up in various ways, which can be found here. In this tutorial, we are using a hosted MySQL instance to get up and running quickly.
- You will need a Kafka instance that will serve as a destination. To get started quickly with Kafka, follow the instructions here. Again, for simplicity, we are using a hosted Kafka instance.
Step 1: Load data into the MySQL database
In this tutorial, we will create a MySQL database in our hosted instance and load it with some sample data.
Use the MySQL CLI to connect to the remote MySQL instance
First, download the repo to set up the sample data. Once downloaded, run the following commands to set up the employees database and associated tables. Then, insert the sample data into these tables by running the following MySQL commands.
$ mysql --host=<hostname> --port=<port> --user=<mysql-user> -p < employees_partitioned.sql
$ mysql --host=<hostname> --port=<port> --user=<mysql-user> -p < test_employees_sha.sql
You may be prompted to enter your MySQL password. The text between the angle brackets must be replaced with the hostname, port, and username based on your MySQL instance.
Once the two scripts are run, the employees database will be created. You can view the created tables by logging into the MySQL CLI and running the following commands.
$ mysql --host=<hostname> --port=<port> --user=<mysql-user> -p
> USE employees;
> SHOW TABLES:

Create a dedicated user with access to the tables
Creating a dedicated user is recommended for better permission control and auditing. Alternatively, you can use Airbyte with an existing user in your database.
To create a dedicated database user, run the following commands against your database.
CREATE USER 'airbyte'@'%' IDENTIFIED BY '<password>';
The right set of permissions differs between the STANDARD and CDC replication methods. For the STANDARD replication method, only SELECT permission is required. SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT permissions are necessary for the CDC replication method.
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'airbyte'@'%';
Your database user should now be ready for use with Airbyte.
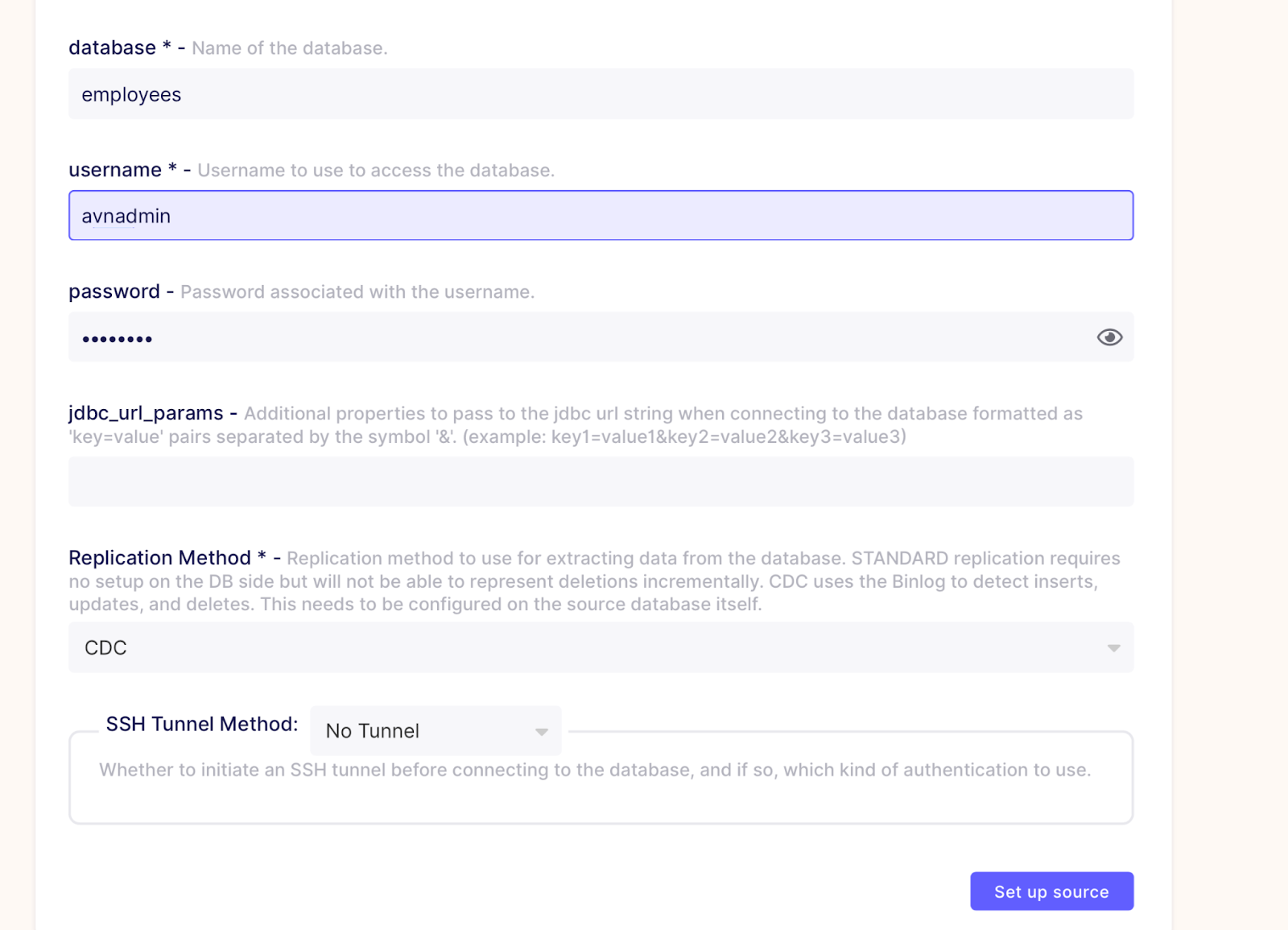
Step 2: Set up the MySQL CDC source
It's easy to create a MySQL source through the Airbyte UI. Make sure to select CDC as the replication method. We have not used SSH in our example. We recommend using SSH tunnels if you are using a public internet network in production.

Step 3: Set up the Kafka destination
Next, we will set up a Kafka destination in Airbyte. In this tutorial, we are running Kafka in our hosted instance and will connect to it using the Kafka client setup locally. Follow the quick start steps to set up the Apache Kafka client locally.
Create a new Kafka topic to sync data
First, we will create a Kafka topic named 'departments' which will be used to write the CDC data.
$ export KAFKA_HEAP_OPTS="-Xms512m -Xmx1g"
$ ./kafka-topics.sh --topic=departments --bootstrap-server <kafka-hostname>:<kafka-port> --create --replication-factor 2 --partitions 1
Next, create a destination in Airbyte as follows.

For all of the remaining settings, we went with the default values that were provided

Step 4: Create a MySQL to Kafka connection
Once the source and destination are set up, you can create a connection from MySQL to Kafka in Airbyte. In the “select the data you want to sync” section, choose the department table and select Incremental under Sync mode.

Using the sync frequency and sync mode options of Airbyte, you can get control to replicate data incrementally and schedule Airbyte to replicate this data.
Once configured, you can see your connection on the Connection tab.

Now that your connection is set up go back into your MySQL shell and run the following commands to add, update and then delete a row in the departments table.

Next, go back to the Airbyte UI, select the connection you just created, and trigger a manual sync.
Once the sync is complete, run the following command in a new terminal window to read the events that persisted to the Kafka topic.
$ ./kafka-console-consumer.sh --topic departments --from-beginning --bootstrap-server <your_kafka_host>:<port>
The screenshot below shows the CDC data for the row you just inserted, updated, and deleted with corresponding timestamps.

The screenshot below shows the CDC data for the row you just inserted, updated, and deleted with corresponding timestamps.
Wrapping up
Here’s what you have accomplished with this tutorial:
- Configure a MySQL Airbyte source
- Configure a Kafka Airbyte destination
- Create a connection that will automatically sync CDC log data from MySQL to Kafka
With a combination of MySQL CDC logs, Airbyte and Kafka, distributed data platforms can be kept in sync and made aware of data changes.
You may be interested in other Airbyte tutorials and Airbyte’s blog. You can also join the conversation on our community Slack Channel, participate in discussions on Airbyte’s discourse, or sign up for our newsletter. Furthermore, if you are interested in Airbyte as a fully managed service, you can try Airbyte Cloud for free!
What should you do next?
Hope you enjoyed the reading. Here are the 3 ways we can help you in your data journey:
Should you build or buy your data pipelines?
Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.

Ready to get started?
Frequently Asked Questions
MySQL provides access to a wide range of data types, including:
1. Numeric data types: These include integers, decimals, and floating-point numbers.
2. String data types: These include character strings, binary strings, and text strings.
3. Date and time data types: These include date, time, datetime, and timestamp.
4. Boolean data types: These include true/false or yes/no values.
5. Spatial data types: These include points, lines, polygons, and other geometric shapes.
6. Large object data types: These include binary large objects (BLOBs) and character large objects (CLOBs).
7. Collection data types: These include arrays, sets, and maps.
8. User-defined data types: These are custom data types created by the user.
Overall, MySQL's API provides access to a wide range of data types, making it a versatile tool for managing and manipulating data in a variety of applications.