Introduction Agent Engine is Airbyte's new platform for scalable data infrastructure that is specifically designed for AI agents. Now available as a private beta , it gives developers the infrastructure to connect agents to hundreds of data sources through a simple, tool-native interface.
The first step in building agent context is actually getting the data onto your platform, and the first step in getting the data is deciding what you need. This is non-trivial: many popular APIs have massive schemas, often poorly documented, with complex object relationships and high usage costs that make "give me everything" a nonstarter. Like most software issues, it's a caching problem, but most caching problems are attention problems in disguise: the knowledge exists, but it's scattered. The trick is to focus it on what you need to solve when you need to solve it.
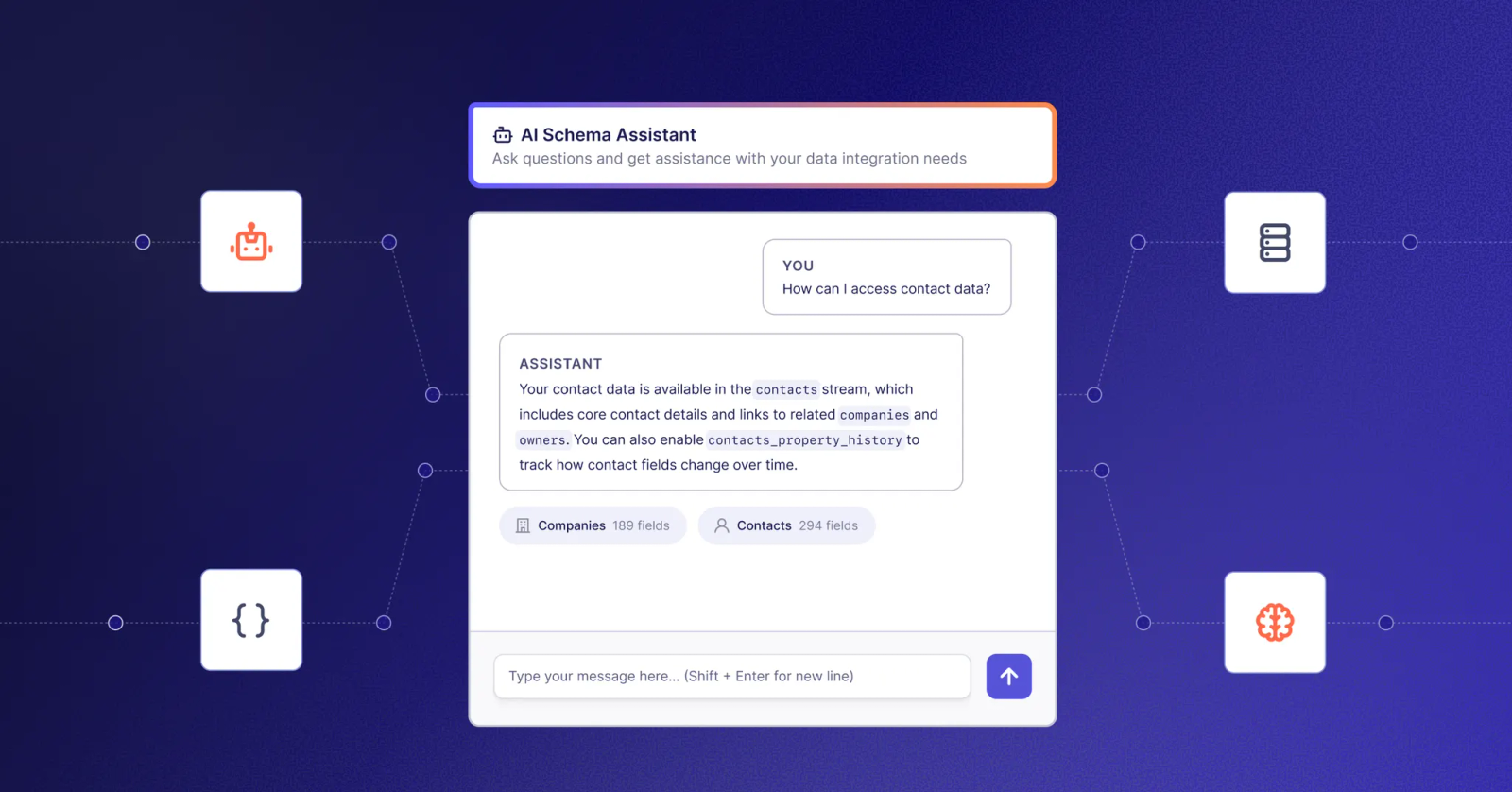
That's why we're introducing Chat With Your Schema, the first in a series of "ontology tools" meant to help Agent Engine users trim the bulk of the bulk sync and get exactly what they need, exactly when they need it.
Now, instead of manually browsing through catalogs and documentation, you can work with an AI assistant with ready access to years of Airbyte's in-house connector expertise, to help you answer the deceptively simple question: what do I actually need?
How It Works Agent Engine operators already have the ability to define "source templates," which express how Airbyte will sync each new customer's data as they connect their Stripe, Github, Salesforce, Google Analytics, etc. They can express common configuration (leaving the secret management to us), which includes, of course, which streams of objects they want to sync.
But now, when configuring their templates, Agent Engine operators can visit a page with a detailed visual representation of the catalog for that particular connector, complete with:
Parent-Child hierarchy Foreign key relationships between streams Field and stream descriptions Data organized into useful categories But instead of just manually exploring this catalog, you can have a conversation with it. Are you mostly after demographic data? Financial transactions? Geo data? Are you trying to use this API as a proxy for a datasource the client lacks? Explain your use case to the model, and it will quickly produce a recommended set of streams.
Under the Hood Offline, we run agents that gather schema information directly from our connectors, then enrich it with documentation (via Firecrawl) and pass it to our "foreign key specialist," which walks the schema stream by stream, assigning and validating relationships.
Then, each catalog is "blessed" by a human auditor, assisted by an agent equipped with websearch and data inspection tools, who together ensure the descriptions are complete, accurate, and verifiable with citations.
As we complete documentation for each new connector, a link appears to the catalog page, where those relationships are expressed in a compact, easy-to-navigate visual model alongside our chat interface. The interface itself is powered by a PydanticAI agent with a curated set of tools that allow it to efficiently query the catalog. We also make use of Pydantic's Deferred Tools feature to give the agent the power to make selections in the UI, as well as to view actions taken by the human user, allowing for true human-agent collaboration.
Once confident with your selections, you just press a button, and thereafter any client who connects data from that source will get exactly those streams. (You even have the option to retroactively apply your selection to existing connectors.)
What's Available Now Chat with Your Schema is live today with 22 "blessed" catalogs, including:
Stripe Salesforce Shopify Instagram Amazon Seller Partners And 17 others Each catalog includes the foreign key annotations, descriptions, and categorization that make the AI assistant genuinely useful for configuration decisions.
What's Next In addition to cataloging more connectors, we are building a suite of next generation agent connectors that will streamline realtime access to source data and facilitate rapid activations. This will include an optional hosted searchable cache, available to operators through an SDK and related set of MCP tools, offloading the sync process to Airbyte entirely. (Chat with Your Schema will become Chat with Your Data!)
From there we plan to support a growing set of data modeling and transformation use cases, with the end goal of enabling operators to build a fully searchable business model directly on the Airbyte platform. Bottom line: We are transforming the process of data configuration from a manual burden into an intelligent, collaborative experience.
Apply to join the private beta today!