New: Airbyte Agents. Context-aware AI, built on your data.
Blog
/
Company Updates
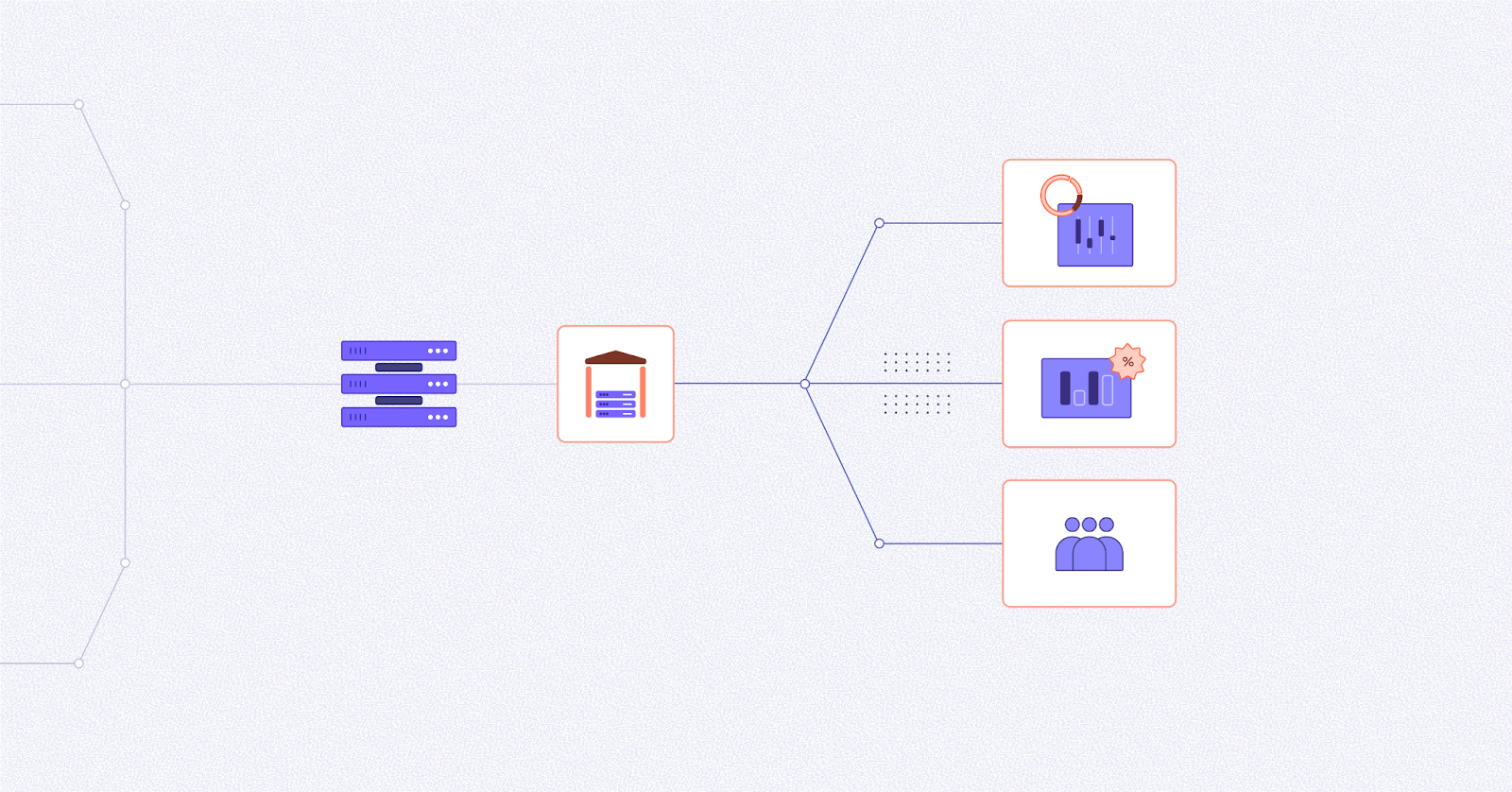
Unlock data activation by sending insights back to your source systems—empower teams with actionable intelligence and drive faster decisions.
Summarize with AI:
About the Author
Jon Whitney
Jon is the CPO of Airbyte. Previously, he was the VP of Product at OpenInvest and director of Enterprise Architecture at AppDynamics.
Be among the first to explore our new platform and get access to our latest features.
Join our newsletter to get all the insights on the data stack