Top companies trust Airbyte to centralize their Data








Ship more quickly with the only solution that fits ALL your needs.
As your tools and edge cases grow, you deserve an extensible and open ELT solution that eliminates the time you spend on building and maintaining data pipelines
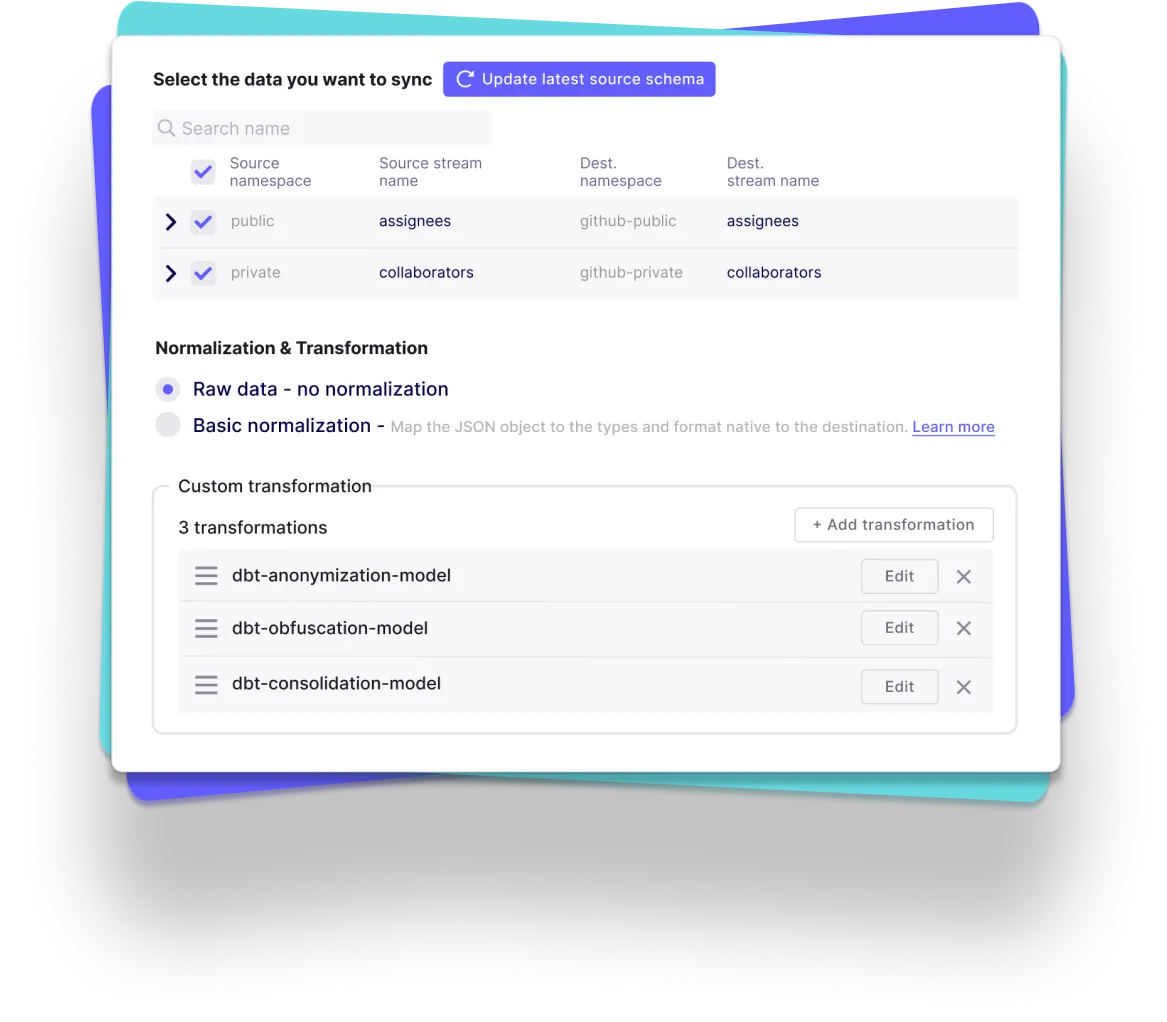
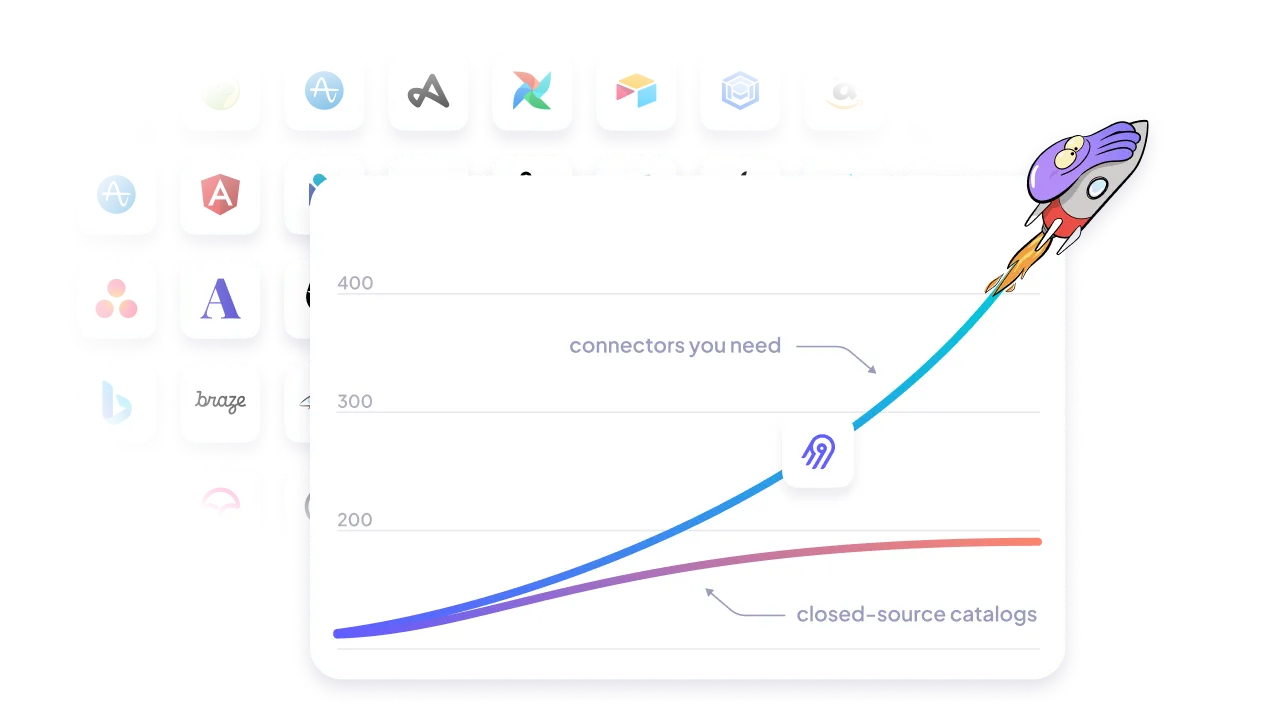
Leverage the largest catalog of connectors
Cover your custom needs with our extensibility

Free your time from maintaining connectors, with automation
- Automated schema change handling, data normalization and more
- Automated data transformation orchestration with our dbt integration
- Automated workflow with our Airflow, Dagster and Prefect integration

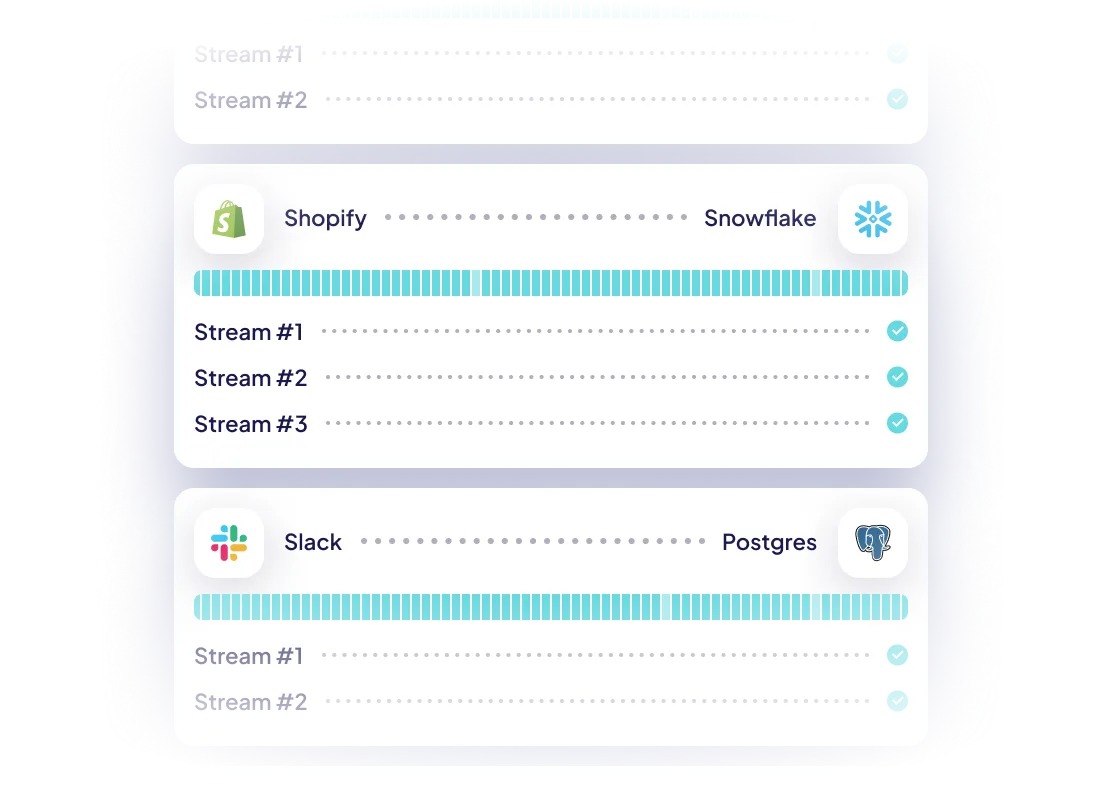
Reliability at every level


Airbyte Open Source
Airbyte Cloud
Airbyte Enterprise
Why choose Airbyte as the backbone of your data infrastructure?
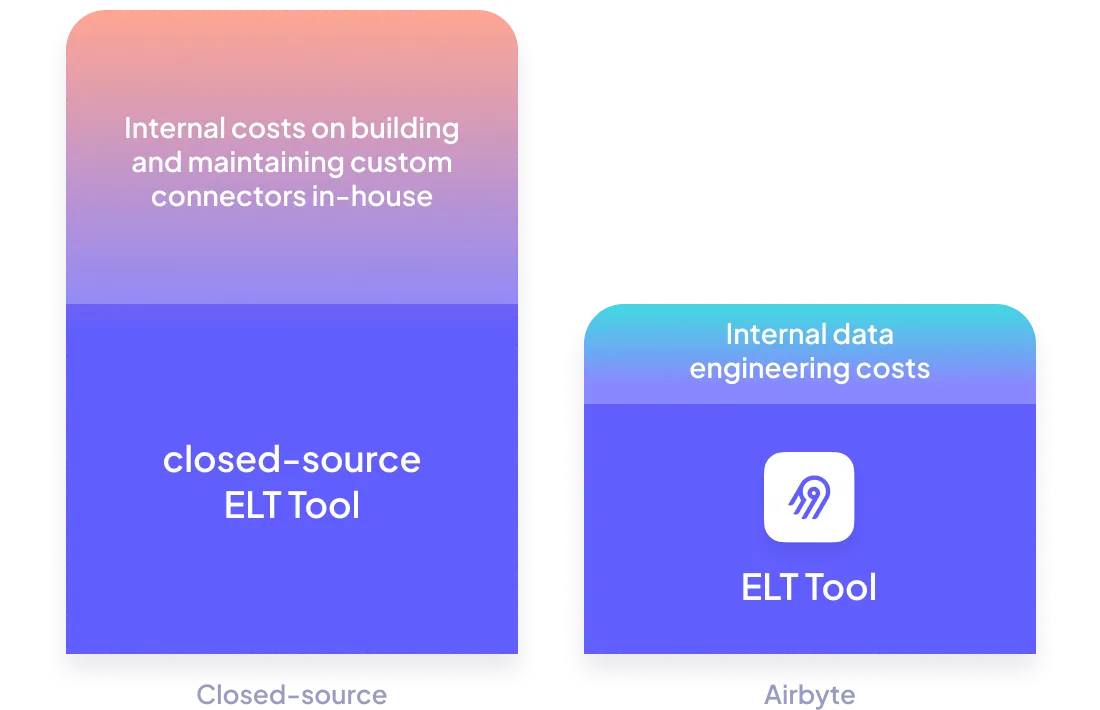
Keep your data engineering costs in check
Get Airbyte hosted where you need it to be
- Airbyte Cloud: Have it hosted by us, with all the security you need (SOC2, ISO, GDPR, HIPAA Conduit).
- Airbyte Enterprise: Have it hosted within your own infrastructure, so your data and secrets never leave it.

White-glove enterprise-level support
Including for your Airbyte Open Source instance with our premium support.


Fnatic, based out of London, is the world's leading esports organization, with a winning legacy of 16 years and counting in over 28 different titles, generating over 13m USD in prize money. Fnatic has an engaged follower base of 14m across their social media platforms and hundreds of millions of people watch their teams compete in League of Legends, CS:GO, Dota 2, Rainbow Six Siege, and many more titles every year.
Ready to get started?
FAQs
What is ETL?
ETL, an acronym for Extract, Transform, Load, is a vital data integration process. It involves extracting data from diverse sources, transforming it into a usable format, and loading it into a database, data warehouse or data lake. This process enables meaningful data analysis, enhancing business intelligence.
Amplitude is a cross-platform product intelligence solution that helps companies accelerate growth by leveraging customer data to build optimum product experiences. Advertised as the digital optimization system that “helps companies build better products,” it enables companies to make informed decisions by showing how a company’s digital products drive business. Amplitude employs a proprietary Amplitude Behavioral Graph to show customers the impact of various combinations of features and actions on business outcomes.
Amplitude's API provides access to a wide range of data related to user behavior and engagement on digital platforms. The following are the categories of data that can be accessed through Amplitude's API:
1. User data: This includes information about individual users such as their demographics, location, and device type.
2. Event data: This includes data related to user actions such as clicks, page views, and purchases.
3. Session data: This includes information about user sessions such as the duration of the session and the number of events that occurred during the session.
4. Funnel data: This includes data related to user behavior in a specific sequence of events, such as a checkout funnel.
5. Retention data: This includes data related to user retention, such as the percentage of users who return to the platform after a certain period of time.
6. Revenue data: This includes data related to revenue generated by the platform, such as the total revenue and revenue per user.
7. Cohort data: This includes data related to groups of users who share a common characteristic, such as the date they signed up for the platform.
What is ELT?
ELT, standing for Extract, Load, Transform, is a modern take on the traditional ETL data integration process. In ELT, data is first extracted from various sources, loaded directly into a data warehouse, and then transformed. This approach enhances data processing speed, analytical flexibility and autonomy.
Difference between ETL and ELT?
ETL and ELT are critical data integration strategies with key differences. ETL (Extract, Transform, Load) transforms data before loading, ideal for structured data. In contrast, ELT (Extract, Load, Transform) loads data before transformation, perfect for processing large, diverse data sets in modern data warehouses. ELT is becoming the new standard as it offers a lot more flexibility and autonomy to data analysts.