Airbyte is an open-source data integration framework that empowers no-code ELT pipelines between any data sources and destinations.
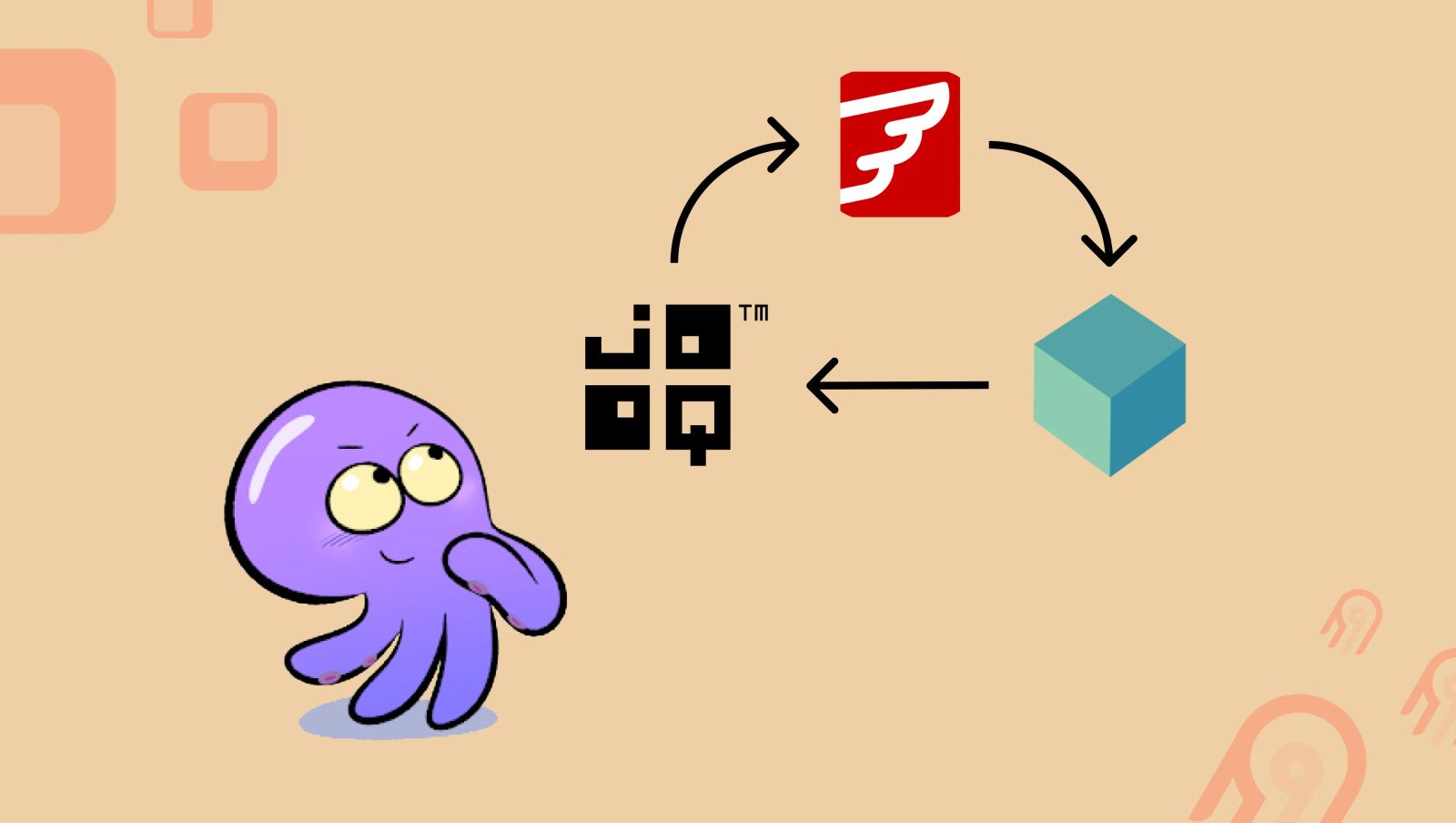
At Airbyte, we use Java as our main language for backend development, Gradle as our build tool, jOOQ as the object-relational mapping library (ORM), and Flyway to manage database migrations. In this blog post, we will describe how we chain these tools and frameworks together to maintain and evolve our internal data models.
How we run Flyway migrations Database migration is the process of managing database schema changes through code. Each time a modification is needed, instead of firing queries to directly alter the tables and columns, developers first write down the queries in a file and run the change programmatically. In this way, the changes are version-controlled, and they can be tested, reversed, and replayed, leading to more reliable schema migration.
We use Flyway to run migrations at Airbyte because it is one of the most frequently used database migration libraries in the Java world. However, there are a few things we do differently from many of the similar setups (e.g. the tutorial from jOOQ) using the same stack.
Write Flyway migration scripts in Java Firstly, we write all of our Flyway migration scripts in Java rather than in SQL. This approach has many benefits. It is much easier to write unit and integration tests for Java code than for SQL. When a migration is related to business logic (e.g. introduce a new connector type), we can reference such business logic from other Java code, instead of redundantly hard coding them in SQL files. In addition, we can write the Flyway migration with the help of jOOQ instead of doing that in plain SQL statements, which provides nice guardrails and handy utilities.
Use testcontainers to run migrations locally Secondly, all local migrations are run and tested against a database in testcontainers , instead of a physical database. In this way, engineers do not need to set up a database locally. Each time, the database initialization and migrations are done from scratch, providing an extra assurance that nothing depends on any special prior condition in a local database. For example, a migration may require that local database to have a default charset of UTF8, or it will fail. Should we test migrations against local databases, the developers who happen to set a different charset for the database on their machines will see exceptions while others don't, which would be very confusing.
Extend Flyway migrations Last but not least, we wrap the Flyway migration inside our own migration classes to add extra features to the migration process. This includes logging all the warnings from Flyway, tracking the trigger of the migrations (e.g. upon server start or by API call), printing out the status and metadata of the migration (like how many migrations are run). Most importantly, whenever the migration is run in a development environment, we dump the database schema into a text file, which is checked into the git repository. In this way, developers are always aware of the changes they have made in the migrations. Our continuous integration (CI) pipeline will run all the migrations as part of the building process and dump the schema as well. If there is any diff in the schema file that has not been committed, the build will fail loudly to remind people about it. This custom feature is inspired from the schema dumping in many other database migration frameworks, for example, Ruby on Rails.
Our database migration development cycle Whenever we need to introduce a change to the database schema, our development cycle can be divided into two steps:
Write and test the Flyway migration Run the migration and update the jOOQ code Step 1 - Write and test the Flyway migration It’s straightforward to write a Flyway migration in Java. We simply create a class that extends from the <span class='text-style-code'>BaseJavaMigration</span> class. Here is an example of what a basic migration class looks like:
The name of the migration class needs to follow the pattern documented here : a single letter to mark the migration type, an arbitrary version separated by an underscore, a double underscore separator, followed by a brief description. We always write versioned migrations, and that's what the first V stands for. For the migration version, we usually use the Airbyte server version at the time the migration is written followed by an increasing number to distinguish between multiple migrations developed at similar times. In the above example, they are "0.35.3" and "001", respectively. Since the naming pattern is nontrivial, we have created specific Gradle tasks (new<database-name>Migration) to automatically generate a new Flyway migration with the proper version and name based on a template .
Typically, inside the migrate method, a SQL statement is prepared and executed, as demonstrated in the Flyway document :
Writing raw SQL statements like this, however, does not fully leverage the advantages of Java. This is when jOOQ comes into play and really shines. By wrapping the database connection inside a jOOQ context, we can enjoy jOOQ's full suite of SQL building helpers. As a result, all the SQL statements get free type checking. They are also SQL dialect-natural, meaning that the same migration file can work on different underlying databases. Although we currently always use Postgres and don't care much about this benefit, it is a possibility should an Airbyte user choose to use a different database.
Step 2 - Run the migration and update the jOOQ code When the migration code is completed and unit-tested, we need to update the jOOQ code based on the latest database schema, and we want it done automatically in our Gradle build pipeline. Normally, this is achievable by using the Gradle Flyway plugin and jOOQ plugin , and making the jOOQ task depend on the Flyway task (as demoed here ). However, there is one complication. Because we wrap the Flyway task inside our own migration classes to augment it, we cannot run a routine Flyway task in Gradle directly. On top of that, we want to run the pipeline with a database from the testcontainers. Coincidentally, Lukas Eder, the author of jOOQ, happened to publish a blog article with an example of how to run Flyway and jOOQ with the testcontainers in Maven one day after we completed this work and merged in the change. But at the time we worked on this problem, there were not many articles talking about doing all these together, let alone having custom migration logic.
The solution is to provide a custom metadata source to the jOOQ code generator, as mentioned in the jOOQ documentation and demonstrated in jooq-meta-postgres-flyway by Michal Sabo. In our case, we create a class that extends from the jOOQ Postgres database and perform all the custom operations in the <span class='text-style-code'>create0</span> method before a jOOQ context is returned. The custom database class in our codebase can be found here . Its skeleton looks like this:
For each database that needs to be migrated, we define the following jOOQ task in the build.gradle file:
Note that the custom meta database class is passed in as the name of the database to the jOOQ code generator. This means that this database class must be compiled before the above Gradle file is executed. Therefore, this class should be defined in a separate Gradle module that is a dependency of the module that generates the jOOQ code in Java. The overall structure of the two modules are:
lib contains all the Flyway migration scripts and the custom meta database class. jooq depends on the lib module. It has a single build.gradle file that defines the jOOQ code generation task as shown above. Now we can run the jOOQ task when compiling Java code, or manually by this command: <span class='text-style-code'>./gradlew :jooq:generate<database-name>Jooq</span>.
With the updated jOOQ code, we can move on to write business logic using jOOQ to manipulate the latest database records.
Things to watch The migration script cannot depend on generated jOOQ code This is the case for two reasons. Firstly, the generated jOOQ code lives under the db-jooq module, which depends on the db-lib module. Since the migration scripts are in the db-lib module, using generated jOOQ code will create a circular dependency. Secondly, because the generated code can change with the database schema, it is possible that a future migration can break previous migration classes. For example, a whole table may be removed, which will wipe out all the record classes from jOOQ after the Java code is regenerated. Therefore, migration code should stick to jOOQ's query DSL APIs and refer to SQL identifiers by strings.
For example, column nullability should be changed like this:
Prepare the migration for unexpected scenarios To successfully update the database schema, a migration must have a correct prediction of the current state of the database. An example is that to add a new table, that table should not already exist. However, there are always bugs and edge cases. It is possible that the database is in a state different from what the migration expects. This is especially the case for us because Airbyte is an open-source software with a large community of developers running the server on their own infrastructures and making custom changes to the database. Apart from thoroughly unit-testing the migration logic, we try to write defensive migration scripts that work for unexpected cases. This means adding extra checks about the current database states. For cases that cannot be handled programmatically, throw exceptions fast with clear messages about what is different from the expected state. Otherwise, write idempotent logic to bypass those cases. For example, to add a new table, instead of calling <span class='text-style-code'>createTable</span>, we can use the <span class='text-style-code'>createTableIfNotExists</span> method to ensure the migration works even if the table already exists.
Conclusion Our entire database setup can be found in the airbyte-db module in our main codebase. To find out more about the detailed implementations, you can reference these files:
If you find this article helpful, please give us a star on the Airbyte project, and follow our engineering blog for more articles like this in the future.
About the author Liren Tu is a Software Engineer at Airbyte.