What Tools Are Out There for Building a Semantic Layer?
As we’ve now learned a lot about the semantic layer, let's see actual tools, focusing on open-source.
The most commonly named tools are Cube.js (recently renamed Cube), MetricFlow, MetriQL, dbt Metrics, or Malloy. Where MetriQL was the first open-source but Transform.co working on a closed-source version that eventually got open-sourced into MetricFlow. Also, dbt announced their metrics system back at Coalesce the Metric System, and turning it now into dbt Semantic Layer (more to come in October at dbt Coalesce Conference). According to GitHub stars, Cube is the fastest growing tool in this area, and already has many integrations including data sources and data visualizations – for example, it integrates with dbt Metrics.
MetricFlow and Cube’s semantic layer overview is fascinating to compare, where Cube talks about headless BI and MetricFlow about the metrics layer. As discussed above, you understand why both try to address not only the metrics part but also data modeling and abstract away all data sources by adding access control, caching, and APIs.
Overview of a Semantic Layer by Cube (top) and MetricFlow (bottom)
When do you need such a tool? There are two initial use cases: First, if you won’t build a significant data architecture, you could start with your sources and access your data sources or cloud warehouse. The second one is when your company size and data-savvy people are growing. More people need transformations, defining metrics, or adding many data and SaaS tools; you need alignment around definitions.
Some trends: Supergrain initially also had a metrics layer but pivoted to personalized marketing. If we look solely at the GitHub stars, it is a bit unfair for MetricFlow as they worked to log on that problem but only open-sourced it, but still, it gives a good impression about cube.js. They also just announced the Unbundling of Looker in combination with Superset. Furthermore, there is a dedicated Semantic Layer Summit.
A deeper comparison of the tools you find on How is this different from. There is an extensive list of closed-source solutions such as uMetric by Uber, Minerva by Airbnb, Veezoo, and more.
🐦 Unpopular Opinion: The Metrics Stores are just BI Tools that evolve into full-fledged BI tools over time [Tweet] Nick Hande, Co-founder of Transform, replied: “I think I actually agree with this. But, I don’t think BI Tools will exist as they do today. Instead, there will be data applications that will rely on semantics expressed in Metrics Stores. The Metrics Store will need governance + discovery that includes graphs(“BI”) + metadata”.
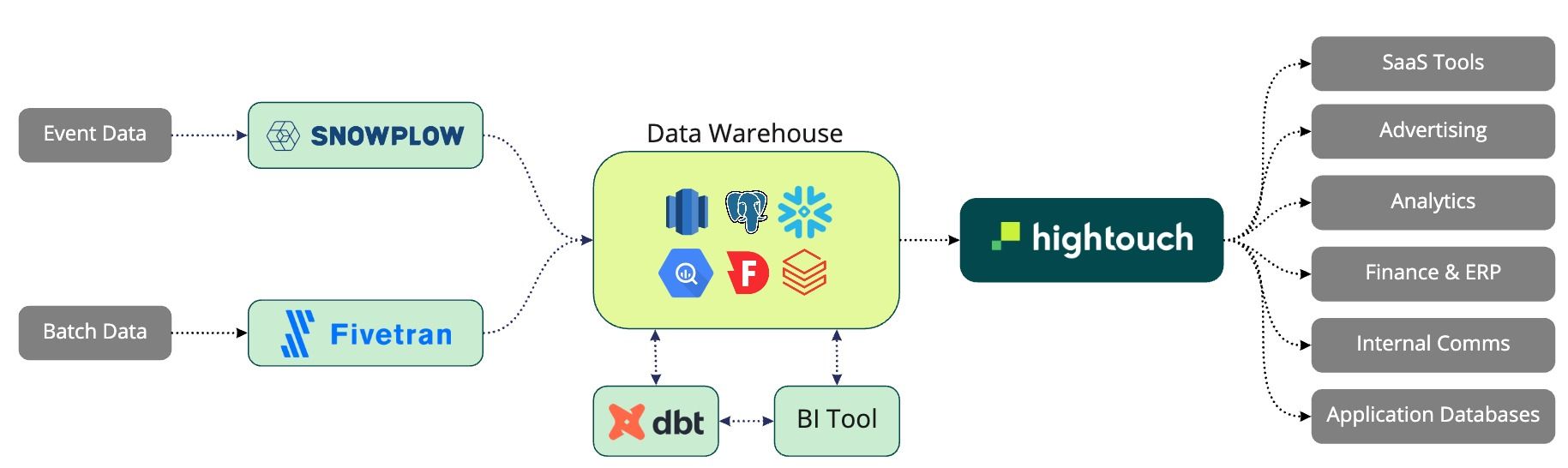
💬 An interesting announcement about the Customer Data Platform (CDP), a relatively new term, and companies already pivoting away from it. Hightouch talks about “legacy CPD”. Fascinating to me, because the new data architecture looks like a semantic layer on top of the data warehouse, or is it just me?
Semantic Layer Challenges
Besides all the positive things mentioned, some challenges come with a semantic layer. First of all, it is another layer that needs integration with many other tools. Another significant downside is having to learn another solution that needs to be operationalized as a critical component of your data stack. The cost of maintaining and creating such a layer is high.
There is also a hidden complexity in generating these queries on the fly. Every query needs to be generated for different SQL dialects–e.g., Postgres SQL and Oracle SQL are not 1:1 the same. That can be both problematic in terms of latency but also in terms of producing a faulty SQL query. The counter-argument is that it’s still easier to maintain copies of data sets and re-do the metrics repetitively inside a BI dashboard.
When you use extensive exposed APIs, you might run into performance issues, as pulling lots of data over REST or GraphQL is less than ideal. You can always switch to SQL directly, but mostly with losing some comfort.
As always, it depends on the criticality of centrally defined metrics that everyone agrees on, or you can live in minor drift away in different tools.
🗣 What others are saying: JP Monteiro is saying in his deep dive: “I find it unlikely that the best practice will still be to have one place to define metrics and one place to define dimensions, once the querying layer part is solved. In fact, lineage between concepts is part of “semantics”: it helps us understand how one concept is related to another —which makes you really question if ‘column-level lineage’ is the right level of abstraction we should talk about: columns are too raw".
Semantic layer vs data mart vs presentation layer
Purpose
Semantic Layer: It serves as a connector between sources of raw data and the presentation layer, providing a collective view of the data and abstracting away the complexities of underlying data structures.
Data Mart: It is a subset of a data warehouse designed to serve a specific department or line of business, containing a tailored set of data optimized for analysis and reporting.
Presentation Layer: In this layer the data is visualized and presented to the end-users, often in the form of dashboards, reports, or applications, making it understandable and actionable.
Content
Semantic Layer: This layer includes different business logic, data definitions, and relationships between various data elements, enabling users to query and analyze data with the help of familiar business terms rather than database terminology.
Data Mart: It contains structured data relevant to a particular business function or area, such as sales, marketing, or finance, organized for analytical purposes.
Presentation Layer: It has a visual representation of data, which includes charts, graphs, tables, and interactive elements, designed to facilitate decision-making and insight generation.
Audience
Semantic Layer: It is primarily designed for data analysts, business intelligence professionals, and other technical users who need to access and analyze data across different sources in a consistent manner.
Data Mart: It serves business users and analysts within a specific department or business unit, providing them with relevant and tailored data for their analytical needs.
Presentation Layer: It caters to a broader audience, including executives, managers, and operational staff, who rely on intuitive and informative visualizations to understand trends, identify patterns, and make informed decisions.
What’s the Difference to OLAP, Data Cataloging, Virtualizations, or Mesh
As the semantic layer is something central and intertwined with lots of related data engineering concepts, we discuss here how they relate to each other.
OLAP Cubes
As part of the semantic layer, the cache layer can be seen as a replacement for modern OLAP cubes such as Apache Druid, Apache Pinot, and ClickHouse. Similar attributes with defining the queries ad-hoc and delivering sub-second query times. OLAP cubes are the fastest way to query your data if you do not have updates in your data.
Compared to an OLAP solution, the benefit of the semantic layer is avoiding reingesting your data into another tool and format; it happens under the hood, for good or worse. A caching layer is another complex piece, as it's always outdated as you add more data; it needs to constantly update its cache as you do not want to query old invalidated data.
That's also where it gets interesting how semantic layer tools solve it. For example, Cube tried to implement with Redis but reverted and built their own caching layer from scratch. On the upside, OLAP cubes have built-in computing where you can run heavy queries.
Data Virtualization and Federation
Data Virtualization comes up in many discussions related to the semantic layer. Still, even more to the semantic layer is data virtualization, with tools such as Dremio that try to have all data in-memory with technologies such as Apache Arrow. Data federation, very similar to virtualization, mostly referred to technologies like Presto or Trino.
These are versions of a semantic layer, including a cache layer with access management, data governance, and many more. It has a powerful option to join data in its semantic layer. In a way, they are the perfect semantic layer, although Dremio, and also Presto have branded themself as an open data lakehouse platform lately. Which brings us to another question.
Is a lakehouse nothing else than a semantic layer?
In a way, they have similar attributes, but a lakehouse includes an open storage layer (Delta Lake, Iceberg, Hudi). In contrast, the semantic layer is more ad-hoc, query-time driven. Still, the lakehouse from Databricks tries to store only once and avoid data movement as much as possible by querying it with their compute engine Photon.
The problem is, the platform itself is not open-source, only storage, and the metrics are not defined in a declarative way. They are mostly entangled in notebooks or UI-based tools.
📝 Dremio has patented database-like indexes on source systems with Data Reflections. They are producing more cost-effective query plans than performing query push-downs to the data sources.
Data Mesh and Data Contracts
Two recent popular terms are Data Mesh and Data Contract. Both are pulling in the same direction of giving more power to the domain experts who know the data best, away from engineers who should be more focused on a stable system.
In my opinion, giving more control also needs an easier way for these domain experts to define their metrics in a standardized way, being declarative directly on the Data Assets, but with a standardized tool—which is the semantic layer for me. But in contrast to data mesh, which is decentralized, the semantic layer fancies a very centralized approach for metrics.
Data Catalogs
A data catalog is another way of centralizing metrics and Data Products. It’s similar to a semantic layer but focuses more on the physical data assets than the metrics query. Plus, it has another focus: providing a Google search to your data assets such as dashboards, warehouse tables, or models. Modern tools such as Amundsen or DataHub allow you to rate and comment on the data assets, adding metadata such as an owner so that people easily find the best data collaboratively set for their job.
The Semantic Warehouse
A Semantic Warehouse is a term I heard from Chad Sanderson for the first time a month ago. He does a great job putting the words semantic layer, semantic mapping, metrics layer, and data catalog on a data map, as seen in the image below.
What’s interesting here is that the semantic layer is directly on top of the apps, services, and DB between semantic mappings and the metrics layer. It acts as a Data Contract between the real world and the data team. In my opinion, this is what a semantic layer is described in great detail above.
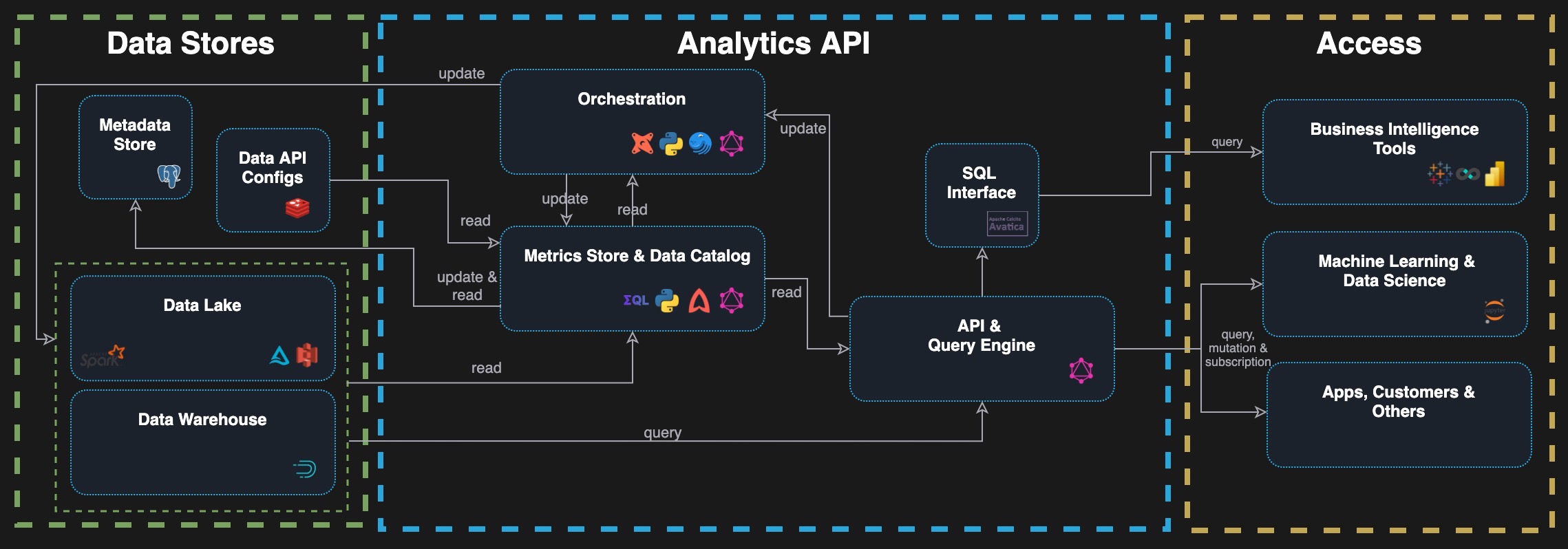
Analytics API
In the above semantic warehouse illustration, the semantic mapping seems to be the data orchestrator, and the metrics layer is the subset of the semantic layer that holds the metrics themselves. This is interesting because I implemented such a thing (parts of it), and I wrote about it in a similar way in Building an Analytics API with GraphQL. I called it Analytics API with its core components of an API and query engine, data catalog, data orchestrator, a SQL connector, and of course, the metrics layer. It has the same function and the same component but is visualized as a single analytics API component. Queries through the access layer connecting heterogeneous data stores.
The semantic layer is an abstract construct that is hard to grasp. It has many touching points with existing concepts and similarities with other upcoming ones.
If it were a new construct, I'd say it's just another buzzword. But as it started in 1991, as seen in the history of the semantic layer, and evolved into the modern data stack and adapted to today's needs.
It's still hard to implement all features we've discussed here; that's the theoretical view. But I believe if you start with getting a more diverse architecture with lots of spread-out tools, the semantic layer has its stands for staying. Start with your basic requirements. Maybe you need a central access layer for people to access data quickly. Or you do not want to add another complex layer with an OLAP cube on top and search for an efficient cache layer. Or most importantly, if you're going to define your metric in a central place with a thin layer, start with the concept of the semantic layer and its definition of metrics.
Learn along the way. Check out the above tools mentioned and see if they work out. These days, the tech makes it very easy to start a POC, e.g., define some of your BI metrics inside a semantic layer and sync it into your BI tool. Try to get a feeling for it.
Besides the must needs such as data integration, transformation at ingest, visualizing, and orchestrating, I see the semantic layer as the next step for defining metrics in a standardized way.
—
If you want to read more, I pulled together an extensive list of other articles on that topic in our data glossary on What is a Semantic Layer.
If you are curious about how we Build the Data Stack and integrate a semantic layer at Airbyte and stay up to date with our Newsletter, we plan to share a hands-on tutorial about it. Or, if you want to chat with 9000+ data people and us, join our Community Slack.
FAQs
How to build a semantic layer?
Before constructing the semantic layer, analyze the data sources and business requirements. Next, determine the definitions, relationships, and important data entities. Then, create a logical data model that satisfies business requirements while abstracting technical complexities. Utilize a business intelligence platform or a data modeling tool to put the model into practice. Finally, ensure that the semantic layer provides precise, consistent, and useful insights by iteratively validating and improving it based on feedback from stakeholders.
How do different business applications use the semantic layer?
Semantic layers serve multiple purposes across various domains within the realm of data management and analytics. In business intelligence (BI) tools, they provide users with a unified perspective of data, streamlining reporting and querying processes. Data virtualization tools leverage semantic layers to seamlessly integrate disparate data sources, thereby enhancing data agility and accessibility. Data analysis tools utilize semantic layers to enhance analytical capabilities and comprehend intricate data relationships. Moreover, within data governance systems, semantic layers play a pivotal role in enforcing standardized data definitions, access restrictions, and compliance guidelines throughout the organization.
How do semantic layers help LLMs better interpret data?
Semantic layers significantly enhance the interpretative capabilities of Large Language Models (LLMs) by providing a structured, contextual framework for data analysis. By abstracting complex data structures and technical specifics, semantic layers enable LLMs to access and analyze data uniformly, thus improving their ability to understand intricate relationships and contextual nuances. This unified approach allows LLMs to deliver more precise and insightful analyses, making them invaluable tools in decision-making processes across various domains. As LLMs apply these layers, they better identify trends, contextualize information, and generate accurate insights, supporting users in navigating and making informed decisions in complex environments. This refined processing aids in bridging the gap between vast data sets and practical, actionable intelligence.
The data movement infrastructure for the modern data teams.
Simon is a Data Engineer and Technical Author at Airbyte. He is dedicated, empathetic, and entrepreneurial with 15+ years of experience in the data ecosystem. He enjoys maintaining awareness of new innovative and emerging open-source technologies.



{kind=link}

{kind=link}