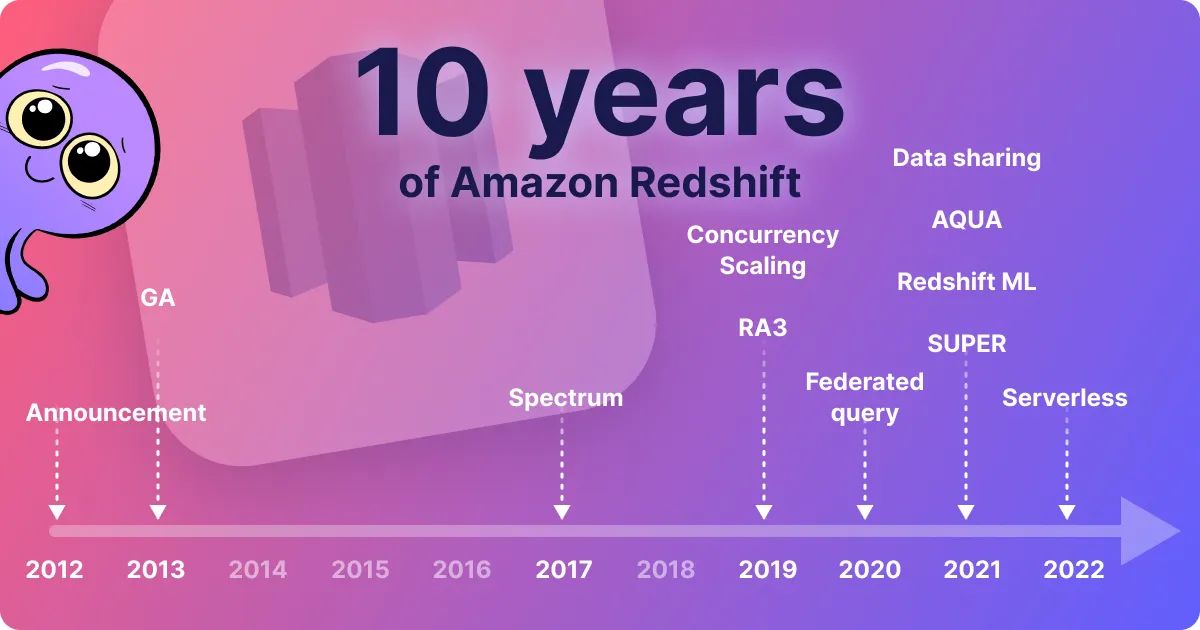
Amazon Redshift debuted a decade ago today . Since then, it has survived the rise and fall of Hadoop, been crowned the fastest-growing Amazon service ever, and successfully evolved to suit the needs of a dynamic data analytics world. Without Redshift at its core, The Amazon Web Services (AWS) data platform would be incomplete.
This blog post will walk you through the evolution of Redshift, from its origin to the present day, detailing the most important architectural shifts that led to the current version of the service. By the end of this post, you will understand how Redshift interacts with other services in the AWS ecosystem and what the future may hold.
To offer diverse points of view throughout this retrospective, I interviewed the former Director of the Amazon.com data warehouse team, as well as a Senior Data Engineer who has been a longtime Redshift user.
2012: Redshift announcement Ten years ago, Andy Jassy – then AWS Senior Vice President – revealed Amazon Redshift at the inaugural AWS re:Invent conference. The new service was presented to the excited audience as “the first fully managed, petabyte-scale cloud data warehouse” and made available on “limited preview”.
During the talk, Andy explained that a two-billion-row data set was used for the initial pilot at Amazon.com, where the data warehouse team tested Redshift and compared it to their existing on-premise data warehouse. The experiment results: at least 10x faster queries for a fraction of the cost .
Andy Jassy announcing Redshift at the inaugural AWS re:Invent conference
Werner Vogels, CTO of Amazon.com, explained the experiment in more detail in his 2012 blog post : Amazon.com’s data warehouse was a multi-million dollar system (consisting of 32 nodes, 128 CPUs, 4.2TB of RAM, and 1.6PB of disk space) that could be replaced with a two 8XL node Redshift cluster, costing less than $32,000 per year.
It's essential to put this within the context of the industry at the time. Enterprises used on-premise data warehouses (like Teradata, IBM, and Oracle) that cost millions to run. The Redshift pricing scheme would open the door for smaller companies to have enterprise-level data warehouses.
To get more details on the early days of Redshift, I interviewed Erik Selberg , former Amazon.com data warehouse team Director and one of the earliest Redshift users. A memorable moment for Erik was seeing the first Redshift petabyte cluster in action:
“We had 100 8XL Redshift nodes spun up to hold the Amazon click log–which was 15 months' worth of clicks on Amazon.com. We couldn't do a full scan of that data in our Oracle behemoths because we'd run into various architectural issues. Teams needing full scans had to do lots of partial queries and put it all together, often taking days. Our goal with Redshift was to do a full scan in an hour. We did it in 9 minutes .” Because of all this, the advent of Redshift was a big revolution, more so when the public finally got access to it.
2013: Redshift becomes generally available Given the success of the “limited preview,” Redshift became “generally available” at the beginning of 2013.
But how could Redshift offer a better price and performance than the existing solutions back then? The combination of these main characteristics made it possible:
Cloud-based: When using on-premises data warehouses, companies must accurately predict their workloads to ensure they have sufficient resources available, which inherently results in over-provisioning. Using the cloud, companies only pay incremental costs for the resources they use, and these resources can be easily scaled as the requirements go up or down.Columnar storage: Redshift stores data for each column sequentially on disk, the opposite of conventional row-based relational databases. When performing a particular query, Redshift reads data only from the columns it requires, which reduces the amount of input/output (I/O) compared to a row-based database. Moreover, Redshift efficiently compresses data by consecutively storing data of a similar nature.Massively parallel processing (MPP): Redshift's ability to distribute and parallelize queries over several nodes is made possible by its massively parallel processing architecture. The nodes were built to handle data warehousing tasks, were linked together through Ethernet, and had substantial local storage.Redshift’s concept of parallelism extends beyond merely query processing, using it for tasks like loading and restoring data. Data can be loaded concurrently from Amazon S3 with a SQL COPY command specifying the bucket's location. Additionally, Redshift creates highly efficient C++ code specific to the query plan and the schema being executed to make query execution as low latency as possible.
Redshift is based on PostgreSQL , and standard drivers over JDBC or ODBC allow you to link SQL-based clients or business intelligence (BI) products.
Redshift cluster architecture When it became generally available, Redshift could be provisioned with anywhere from 1 to 100 nodes, allowing for easy scalability in response to fluctuating storage and performance needs.
You also had a choice of two node types when provisioning a cluster:
Extra large nodes (XL) with 2TB of compressed storage. Eight extra large nodes (8XL) with 16TB of compressed storage. The above meant you could start with a 2TB capacity and scale up to a petabyte or more. You would pay $0.85 per hour for a 2TB node without upfront costs or get Redshift for less than $1,000 per TB per year with a three-year reserved instance fee.
Redshift was fully managed from the get-go, making administration and management more straightforward than other solutions.
The broad adoption of Redshift was a significant turning point for BI and the data world in general. It dramatically improved performance, cost, and management compared to existing data warehousing options. As Tristan Handy – Founder of dbt Labs – mentions , “when I first used Redshift in 2015, I felt like I had been granted superpowers.”
2017: The data lakehouse comes to AWS By 2017, businesses were storing unprecedented amounts of data. Data Science and Machine Learning (ML) became more relevant for companies, so they started to have more diverse use cases and heterogenous data formats than ever before. The data lake architecture became prominent, and so did the need for data professionals to query and integrate disparate data.
As a result, companies were storing massive amounts of data in services like Amazon Simple Storage Service (S3) but not necessarily in their Redshift data warehouses for analysis, as described by AWS . The main reason is that you had to manually load data to Redshift and provision clusters against the storage and compute requirements you needed.
The solution that the engineers at AWS provided was Redshift Spectrum , which became generally available in 2017.
Redshift Spectrum Spectrum is a feature that allows you to run SQL queries against data in S3 from Redshift. It has been one of the most impactful features introduced to Redshift because it effectively extended the data warehouse storage to exabytes.
Redshift Spectrum also reduces architecture complexity: because many systems already store data in S3, accessing it directly in its native format rather than transforming it and loading it elsewhere is pretty handy. Moreover, this built-in feature lets you power a data lakehouse architecture to join and query data across your data warehouse in Redshift and data lake in S3.
To better understand this and other coming features, I talked with Sergio Ropero , a Senior Data Engineer who has been using Redshift for more than five years in two companies. He explained that, in both cases, he was responsible for the Redshift cluster management and data platform architecture using the AWS ecosystem.
Regarding this feature, Sergio mentions, “we had some use cases in which Spectrum was handy. But it’s also true that the data should be properly partitioned, and the user access has to be controlled to avoid surprises in the billing.”
Given that Spectrum is an integrated component of Redshift, your preexisting queries and BI tools will continue to function normally. AWS uses a 1:10 fan-out ratio from the Redshift compute slice to the Spectrum instance. The Spectrum instances are automatically spin-up during query execution and released subsequently.
Spectrum’s architecture offers several advantages:
It elastically scales compute resources separately from the S3 storage layer. It leverages the Amazon Redshift query optimizer to generate efficient query plans. It operates directly on source data in its native format (text, Parquet, ORC, AVRO file format , etc.) Redshift Spectrum architecture 2019: Redshift separates compute from storage As the number of users and applications that access the data warehouse grows, the query throughput decreases. This is particularly noticeable when there are spikes in the number of queries, for example, on Monday mornings when many analysts are interested in querying data or business people are refreshing their dashboards.
In the event of query spikes, Redshift would queue queries until sufficient compute resources became available, so the queue would inevitably grow and grow. You had two alternatives for configuring the cluster to deal with this problem: Over-provisioning resources to deal with the spikes (wasting money on days with typical workloads) or planning for typical workloads, dooming analysts to a decreased performance.
Concurrency Scaling To solve the above challenge, AWS launched Concurrency Scaling for Redshift in 2019. In short, you can now set up Redshift to dynamically boost its cluster's processing power in response to an increase in the number of concurrent queries it must handle. Once the spike has passed, the extra processing resources are automatically shut-down.
“The feature is very useful. It is meant to help on usage peaks so that the queries can land in another cluster, handled automatically by the AWS team, and not remain forever in a queue,” says Sergio.
The number of additional Concurrency Scaling clusters can be set up to a maximum of 10, with the option to request more if necessary. Redshift will ramp up a sufficient number of extra clusters to manage the influx. You can assign additional clusters to individual users or queues as needed.
According to Werner Vogel’s 2018 blog post on performance optimization , 87% of Redshift users didn’t have significant queue wait times in the first place; meanwhile, the other 13% experienced bursts of concurrent demand averaging 10 minutes at a time. With the introduction of Concurrency Scaling, all users experienced a consistently fast performance, even with thousands of simultaneous queries.
The 2022 Amazon Redshift Re-Invented paper shows how Redshift achieves linear query throughput for hundreds of concurrent clients thanks to Concurrency Scaling.
Redshift Concurrency Scaling RA3 nodes Scaling Redshift in general (not just during query spikes) was, in many cases, not cost-effective in the past because compute and storage could not be provisioned independently. You only had the option to select between dense compute (DC2) or dense storage nodes (DS2) . That changed with the introduction of RA3 nodes with managed storage near the end of 2019.
The launch of Redshift Managed Storage (RMS) – which allowed the separation of compute and storage – was one of Redshift’s most significant architectural changes in the last decade. Since you can add more storage without raising computing costs or add more computing without increasing storage costs, you can now scale cost-effectively.
According to Sergio, “RA3 has been the best Redshift improvement I have seen. It’s extremely useful in terms of resource management. Since we migrated to RA3 nodes, we forgot about running out of disk space and cluster resizing (with all the overhead it implies). With dense compute and storage nodes, you needed to properly handle the storage and compute usage based on the current needs not to be overcharged – and that fine-tuning was complex.”
Using the AWS Nitro System , RA3 nodes have both high-bandwidth networking and high performance with solid-state drives (SSDs) as their local caches. RA3 nodes use SSDs for hot data and Amazon S3 for cold data.
Redshift cluster with RA3 nodes 2020: Query federation comes to Redshift Redshift Spectrum, released in 2017, was developed by AWS engineers to expand Redshift's query capability beyond the data warehouse, enabling you to query data in S3. Next, they took note of the growing popularity of distributed query engines like Presto , which enable query federation.
Query federation allows you to access data from various systems using a single query. For example, you can join historical log data stored in your data lake with customer data stored in a MySQL relational database.
The growing success of query engines in recent years is a direct result of analysts' need for easy access to data across the organization, regardless of where the data is stored .
Federated query In 2020, AWS expanded Redshift’s compatibility within the AWS ecosystem by launching Federated Query . With Redshift's federated queries, you can query across Redshift and S3 along with live data in other databases, such as Amazon RDS and Amazon Aurora .
When I asked Sergio about this feature, he mentioned that he didn’t use it, but he thinks “it can be useful, so you don’t need to ETL data into Redshift, for example. But it may also come with caveats, like being careful of access control and source database utilization.” The last one means that it can be dangerous to query production databases directly, as they can get overloaded and decrease application performance.
2021: Machine Learning and semi-structured data come to Redshift Unlike past years when Redshift's new key features focused on enhancing a specific area, new features in several areas were introduced throughout 2021. Let's go over the most important ones.
Data Sharing There are numerous valid reasons you may want to store data in distinct Redshift clusters, including decentralized management, isolation of development and production environments, and better load balancing. However, sharing data presented challenges in the past, as you needed to manually move data from one cluster to another.
The introduction of Data Sharing in 2021 allows you to share data with clusters within the same account, other accounts, or across regions. You can also share data at many levels, including databases, schemas, tables, views, columns, and user-defined SQL functions.
AQUA Remember the RA3 nodes introduced in 2019? They got even faster in 2021 with the Advanced Query Accelerator (AQUA) introduction.
AQUA is a novel distributed hardware that serves as a cache layer for Redshift Managed Storage. Essentially, AQUA automatically boosts specific types of queries and is offered at no extra cost with some RA3 nodes.
AQUA stores hot data for clusters on local SSDs, decreasing the latency associated with getting data from a regional service such as S3 and reducing the requirement to hydrate cache storage. Redshift detects relevant scan and aggregation operations and sends them to AQUA, which performs the operations against the cached data.
Redshift ML Redshift ML allows you to use familiar SQL syntax to train and deploy Machine Learning (ML) models within your data warehouse. This newly launched service applies ML to data, allowing you to add ML predictions to your analysis and even surface them through BI tools.
Redshift ML uses Amazon SageMaker (a fully managed ML solution) internally. Because of this connectivity, you only need to provide data, metadata, and a variable to predict, and Redshift ML will automatically select, tune, and deploy the optimal ML model. This allows users with minimal experience in ML to reap its benefits.
SUPER data type With the introduction of the SUPER data type , Redshift now offers a quick and flexible solution to ingest and query semi-structured, schema-less data, such as JSON. This means you don't have to worry about the schema of the incoming document and can load it directly into Redshift.
A JSON document can be shredded into several columns or a single SUPER data column. After the data is loaded into SUPER columns, you can use the PartiQL query language to analyze the data.
As depicted in the diagram above, by 2021, Redshift had become the cornerstone of a cutting-edge data platform, handling more diverse data types and being more interconnected within AWS than ever.
2022: Redshift goes Serverless There was no innovation slowdown in 2022; on the contrary, Redshift adopted a few key features that appear to be early indicators of the future. The most important ones? Redshift Serverless, followed by automated materialized views.
Amazon Redshift Serverless In cloud computing, a serverless approach removes the burden of infrastructure management from end users. Redshift Serverless , the newest revolutionary offering from AWS, aims to achieve precisely that. The service was introduced at the 2021 re:Invent conference and became generally available in 2022.
Redshift Serverless eliminates the need for cluster or node provisioning or management. You won’t even see the concept of nodes in your dashboard.
Of course, you can tweak a few things. For example, if you want faster query times, the standard recommendation from AWS is to add more Redshift Processing Units (RPUs) to your instance. Redshift Serverless automatically adjusts resources and scales as needed to maintain optimal concurrency within your established cost control restrictions.
Additionally, since you only pay for Serverless when queries are run, you don't have to worry about pausing and resuming to optimize costs, as you do with provisioned clusters.
This level of automation makes Redshift Serverless a game-changer . As Rahul Pathak, AWS VP of Relational Databases, puts it , “The serverless preview was one of the most widely used that I’ve seen in my 10+ years at AWS.”
Automated Materialized Views Using materialized views in data analytics is key for performance improvement. Materialized views save precomputed query results for future similar queries, improving query efficiency by skipping multiple processing steps and returning the pre-computed results immediately.
But materialized views must still be created, monitored, and updated manually. To alleviate this overhead, AWS has introduced Redshift’s Automated Materialized View (AutoMV) capability – which became generally available in 2022. AutoMV not just monitors and updates materialized views, it goes a step further and automatically creates them for queries with typical recurring joins and aggregations using AI.
This blog post details the results of a performance test on an industry benchmark, which revealed that AutoMV improved speed by up to 19% .
AutoMV is another of the AI-based automated features that Redshift supports, and it comes to complement features like AutoWLM and automatic table optimization to make the user’s life easier.
Conclusion Ten years have passed since the first petabyte-scale cloud data warehouse was introduced. During that time, it has matured and adapted to meet the demands of an ever-evolving data analytics ecosystem.
Although the introduction of the service was groundbreaking, it was not without flaws : “Back in the day, Redshift was operationally problematic. When a node would go down, the 9 minute query would take 2 hours. This would gum up scheduled queries for hours, causing major business pain. I'm pleased to say that over the past few years, they've really invested in fixing that. It isn't something that makes re:Invent, but I think it's the most important thing they've done since launch,” shares Erik Selberg, which is a reassurance that the Redshift of today is increasingly reliable and robust.
It’s also important to note that the fact that Redshift is such a powerful tool doesn’t mean it should be used to address every data analytics challenge. According to Erik, “Redshift fundamentally excels as a classic data warehouse: it needs a well-formed schema and delivers results against said schema with mind-blowing performance.” Professionals well-versed in data architecture and modeling are still required to get the most out of Redshift.
Because of the above, much work still goes into shaping and schematizing data, but that starts to change as the service becomes smarter. When I asked Erik about the future of Redshift, he mentioned that we will see “a lot of investment in throwing AI at queries to understand the optimal schemas and automatically creating them.”
I couldn’t agree more. Looking at some of the latest features, we see a trend: increased automation . In the future, we can expect automation will not only manage workloads, materialized views, and optimize tables and schemas, it will also handle aspects like data governance and compliance. For example, “scanning data for things like SSNs and alerting if found,” says Erik.
Redshift and other cloud-based data warehouses are not alone in adopting higher levels of abstraction and automation. The entire ecosystem of data tools is experiencing the same. What does this mean for data professionals, though? The advent of more sophisticated tooling has meant a sea of change in the nature of data professionals' work, moving from the mundane to the strategic, as I explored in a previous article . This frees up experts to take care of higher-level challenges, such as data quality, security, management, architecture, etc., where their expertise is most needed.
Today, Redshift is the backbone of the AWS data analytics ecosystem. The service is robust and scalable. It can ingest structured and semi-structured data, query operational databases and data lakes and simplify the most complex analysis, such as machine learning. There may come a day when Redshift becomes so abstracted and automated that it will essentially run and manage itself. But, as Erik says, “we're still early days on the ecosystem.”
For my part, I look forward to seeing what the future brings.