Your organization likely collects large amounts of data in various systems such as databases, CRM systems , application servers, and so on. Accessing and analyzing data that is spread across multiple systems can be a challenge. To address this challenge, data integration can be used to create a unified view of your organization's data.
Modern enterprises face a critical inflection point where traditional data integration approaches struggle to keep pace with exponential data growth and real-time decision-making demands. While legacy ETL platforms often require sizable engineering teams and incur unsustainable operational costs due to their complexity, organizations now have access to cloud-native platforms that process petabytes of data daily without vendor lock-in, enabling teams to focus on business value rather than infrastructure maintenance.
If you agree that your organization could benefit from having a unified view of all of its data, here are some questions you will need to ask yourself to come up with a data integration strategy:
Which data integration type should you choose? Which data sources will you need to collect data from? Where will you integrate the data? Should you build or use a data integration tool? How will you transform the data? What are your security and compliance requirements? How will you handle data quality and governance? What Is Data Integration and Why Does It Matter? At a high level, data integration is the process of combining data from disparate source systems into a single unified view. This can be accomplished via data virtualization, application integration, or by moving data from multiple sources into a unified destination. These data integration methods are discussed below.
Manual integration Before implementing a systematic approach to data integration, organizations may initially make use of manual integration—analysts manually log into source systems, export data, and create reports. This strategy is time-consuming, poses security risks, can overload operational systems, and produces reports that quickly become outdated.
Data virtualization With data virtualization, data remains in place while a virtualization layer makes multiple sources appear as a single store. Although convenient, this can bottleneck performance and still runs analytics workloads on operational systems.
Application integration Applications can also be linked directly (point-to-point, ESB, iPaaS) so they share data. This often creates many duplicate copies, increases network traffic, and still risks overloading operational systems.
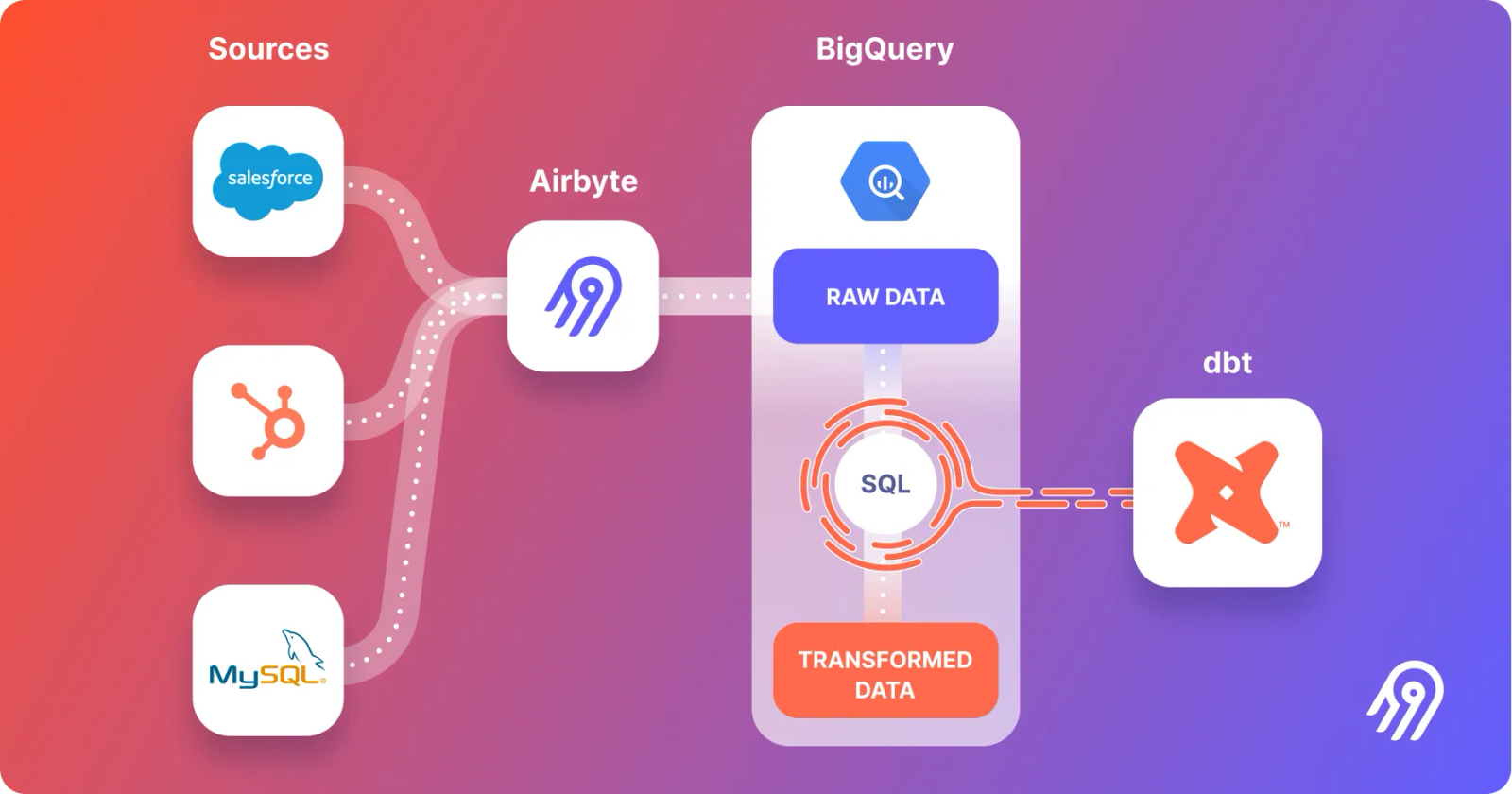
Moving data to a unified destination Sending data into a centralized system—database, data warehouse, data lake , or data lakehouse—creates one place to access and analyze all organizational data.
What Are the Key Benefits of Data Integration Into a Unified Destination? Create a single source of truth – Data is easily accessed by BI and analytics tools, enabling better decisions and a complete organizational view.Analyze data faster with dedicated technology – Warehouses/lakehouses are optimized for big-data analytics.Transform data in a single location – Cleansing, normalizing, and enriching data can follow one common methodology.Improved security – Analysts query the central system instead of production systems.Reduce operational risks – Heavy analytics jobs no longer interfere with operational workloads.Cost optimization – Consolidating data integration reduces licensing costs and maintenance overhead compared to managing multiple point-to-point connections.Enhanced compliance – Centralized data governance enables consistent application of regulatory requirements and audit trails.Which Data Integration Techniques Should You Choose: ETL vs. ELT? ETL (extract-transform-load) and ELT (extract-load-transform) are the two most popular techniques.
The ETL method was once preferred due to high on-prem compute/storage costs. Falling cloud costs now make ELT more attractive. Data integration with ETL ETL transforms data before loading it into the destination. Drawbacks include rigid up-front modeling, potential data loss, and costly re-ingestion when requirements change.
Data integration with ELT ELT loads raw data first, then transforms it in-place (often with dbt ). Benefits include:
Access to untouched raw data Flexibility to create new transformations later Empowered analysts who don't need pipeline changes Modern hybrid approaches now dominate the enterprise landscape, with organizations using ETL for structured transaction data requiring pre-load compliance validation while leveraging ELT for analytics and machine learning workloads. This strategic flexibility allows teams to optimize for both speed and governance requirements without compromising on either dimension.
How Do You Select the Right Storage Technology for Data Integration? Storage technology
Best for
Typical Airbyte destinations
Databases
Transactional processing, moderate analytics
MySQL, Oracle, Postgres, MongoDB
Data warehouses
Large-scale analytics on structured data
Amazon Redshift, Google BigQuery, Snowflake
Data lakes
Cheap storage of vast raw/unstructured data
Amazon S3, Google Cloud Storage, Azure Blob
Data lakehouses
Combine warehouse performance with lake flexibility
Databricks Lakehouse, AWS Lake Formation
Key Selection Criteria When choosing storage technology for your data integration strategy, consider:
Performance Requirements : Data warehouses excel at complex analytical queries on structured data, while data lakes handle vast volumes of unstructured data cost-effectively. Data lakehouses provide the benefits of both architectures.Cost Considerations : Storage costs vary significantly between solutions. Data lakes offer the lowest per-gigabyte storage costs but may require additional processing for analytics. Data warehouses provide optimized performance but at higher storage costs.Scalability Needs : Cloud-native solutions like Snowflake and BigQuery offer elastic scaling that matches usage patterns, while traditional databases may require manual capacity planning.What Are Modern Data Integration Architectures and Frameworks? The evolution from monolithic to distributed architectures defines the modern data integration landscape , addressing scalability and agility demands across hybrid environments. Organizations are increasingly adopting decentralized approaches that balance domain ownership with unified governance.
Data mesh architecture Data mesh decentralizes data ownership to domain-specific teams while treating data as autonomous products with explicit service level agreements. This framework rests on four foundational pillars: domain-oriented ownership, data-as-a-product mentality, self-serve infrastructure, and federated governance.
Implementation Benefits: Domain teams gain autonomy over their data products while maintaining consistency through shared infrastructure and governance frameworks. This approach reduces bottlenecks in centralized data teams while ensuring quality and interoperability.
Event-driven data integration Event-driven architectures replace traditional batch polling with real-time data capture triggered by business events, eliminating latency and reducing source system load. Change Data Capture (CDC) technology scans database transaction logs with near-zero operational impact, while message-queuing platforms like Apache Kafka ingest events concurrently with application databases.
Real-Time Benefits: Organizations achieve millisecond-level data freshness for time-sensitive applications like fraud detection, personalization engines, and operational dashboards while minimizing impact on source systems.
Cloud-native integration platforms Cloud-native architectures leverage containerization, microservices, and serverless computing to provide elastic scaling, high availability, and cost optimization. These platforms automatically handle infrastructure management, allowing teams to focus on business logic rather than operational concerns.
Operational Advantages: Kubernetes-based deployments provide automatic scaling, disaster recovery, and resource optimization. Organizations achieve 99.9% uptime while reducing operational overhead by up to 60% compared to traditional on-premises solutions.
How Do You Overcome Common Data Integration Challenges? Schema Evolution and Compatibility Data sources frequently change schemas without notice, breaking downstream pipelines and analytics. Modern data integration platforms address this through automated schema detection, backward compatibility testing, and graceful handling of schema changes.
Solution Strategies:
Implement schema registry systems to track and validate changes Use schema evolution policies that maintain backward compatibility Deploy automated testing that validates schema changes before pipeline deployment Establish data contracts between producers and consumers Data Quality and Consistency Inconsistent data formats, missing values, and quality issues across multiple sources create unreliable analytics and poor business decisions.
Quality Assurance Approaches:
Implement data quality checks at ingestion time Use data profiling to understand source data characteristics Deploy automated data validation rules based on business requirements Establish data quality metrics and monitoring dashboards Security and Compliance Management Organizations must maintain security and compliance across multiple data sources while enabling analytics access. This requires balancing data accessibility with governance requirements. Meeting that bar means keeping records, and managed providers now offer 365 days of logging so every data access and change stays auditable.
Governance Solutions:
Implement role-based access control (RBAC) with fine-grained permissions Use data masking and encryption for sensitive information Deploy audit logging for all data access and modifications Maintain compliance documentation and automated reporting How Do You Ensure Data Quality Through Contracts and Governance? Data contracts serve as formal agreements between data producers and consumers, defining schema specifications, quality standards, and evolution rules that prevent integration failures caused by unexpected changes.
Implementing effective data contracts Effective contracts include schema specifications (e.g., JSON Schema, Apache Avro), SLAs for data freshness, error-handling protocols, and clear ownership and change-management processes.
Automated quality enforcement Automated testing frameworks validate data against contract specifications during pipeline execution, blocking non-compliant data and alerting stakeholders when violations occur. Version control enables backward-compatibility testing and coordinated updates.
Governance Framework Implementation Establish clear data ownership, lineage tracking, and impact analysis capabilities. Modern data catalogs provide searchable inventories of data assets with business context, technical metadata, and usage patterns.
What Are the Best Data Integration Tools Available Today? Airbyte The leading open-source ELT platform with over 600 connectors and a comprehensive connector development kit . Airbyte provides enterprise-grade security with SOC 2 and ISO 27001 compliance, role-based access control, and deployment flexibility across cloud, hybrid, and on-premises environments.
Key capabilities include:
600+ pre-built connectors covering databases, APIs, files, and SaaS applicationsNo-code connector builder for custom integrations without development overheadEnterprise security with end-to-end encryption and comprehensive audit loggingFlexible deployment options including cloud-managed and self-hosted environmentsReal-time monitoring with automated alerting and pipeline health dashboardsAlternatives 💡 Suggested read: Top ETL Tools For Data Integration
Tool Selection Criteria When evaluating data integration tools, consider:
Connector Ecosystem : Assess available pre-built connectors for your data sources and the ability to develop custom connectors when needed.Scalability and Performance : Evaluate the platform's ability to handle your current and projected data volumes while maintaining acceptable performance levels.Security and Compliance : Ensure the platform meets your security requirements and compliance mandates such as SOC 2, GDPR, or HIPAA.Total Cost of Ownership : Consider licensing costs, infrastructure requirements, and operational overhead when comparing solutions.How Do You Plan a Successful Data Integration Migration? Assessment and Planning Phase Begin with a comprehensive audit of existing data sources, integration patterns, and business requirements. Document current pain points, performance bottlenecks, and compliance gaps to establish migration priorities.
Phased Migration Strategy Implement a gradual migration approach that minimizes business disruption:
Pilot Phase : Start with non-critical data sources to validate the new platformCore Systems : Migrate high-value, stable data sources that provide immediate ROIComplex Integrations : Address legacy systems and complex transformationsOptimization : Fine-tune performance and implement advanced featuresConclusion Data integration provides a unified view of organizational data, enabling better decision-making and operational efficiency. Modern best practice favors ELT pipelines that centralize raw data into a warehouse, lake, or lakehouse, where it can be transformed as needed.
The future of data integration lies in intelligent, cloud-native architectures that combine the flexibility of domain ownership with the governance of centralized oversight. Organizations that adopt modern data integration platforms with strong connector ecosystems, enterprise-grade security, and deployment flexibility will achieve significant competitive advantages through faster time-to-insight and reduced operational costs.
Success in data integration requires careful planning, phased implementation, and ongoing governance. By focusing on business outcomes rather than technology features, organizations can build scalable data ecosystems that adapt to changing requirements while maintaining compliance and operational excellence.
Frequently Asked Questions What is the main goal of data integration? The primary goal of data integration is to create a unified view of data scattered across different systems. By consolidating data into a single destination or virtualized layer, organizations can improve decision-making, streamline operations, and reduce risks tied to siloed information.
What’s the difference between ETL and ELT in data integration? ETL (extract-transform-load) transforms data before it reaches the destination, while ELT (extract-load-transform) loads raw data first and applies transformations in place. ELT is generally preferred today because it provides greater flexibility, scalability, and access to untouched raw data for analytics and machine learning.
How can companies ensure data quality during integration? Organizations can maintain high-quality data by using automated validation rules, schema registries, and data contracts that set clear expectations between producers and consumers. Continuous monitoring, profiling, and governance frameworks help ensure data remains accurate, consistent, and reliable.
Which storage option is best for integrated data? The best choice depends on your use case. Databases work well for transactional data, warehouses for structured analytics, data lakes for unstructured data at scale, and lakehouses for combining both performance and flexibility. Cloud-native options like Snowflake or BigQuery offer elastic scaling and simplified management.
Suggested Read
Big Data Integration
Data Integration Best Practices
Data Integration Framework
Data Integration Workflow
Database to Database Integration
Enterprise Data Integration