If you’re a data practitioner, you’ve probably heard of Change Data Capture (CDC) and may even incorporate it in your data architecture, but do you understand how it works? Often, data teams employ a particular type of CDC without realizing that there may be more efficient implementations; I know this because it happened to me.
This post will define Change Data Capture, its benefits and the various implementation approaches.
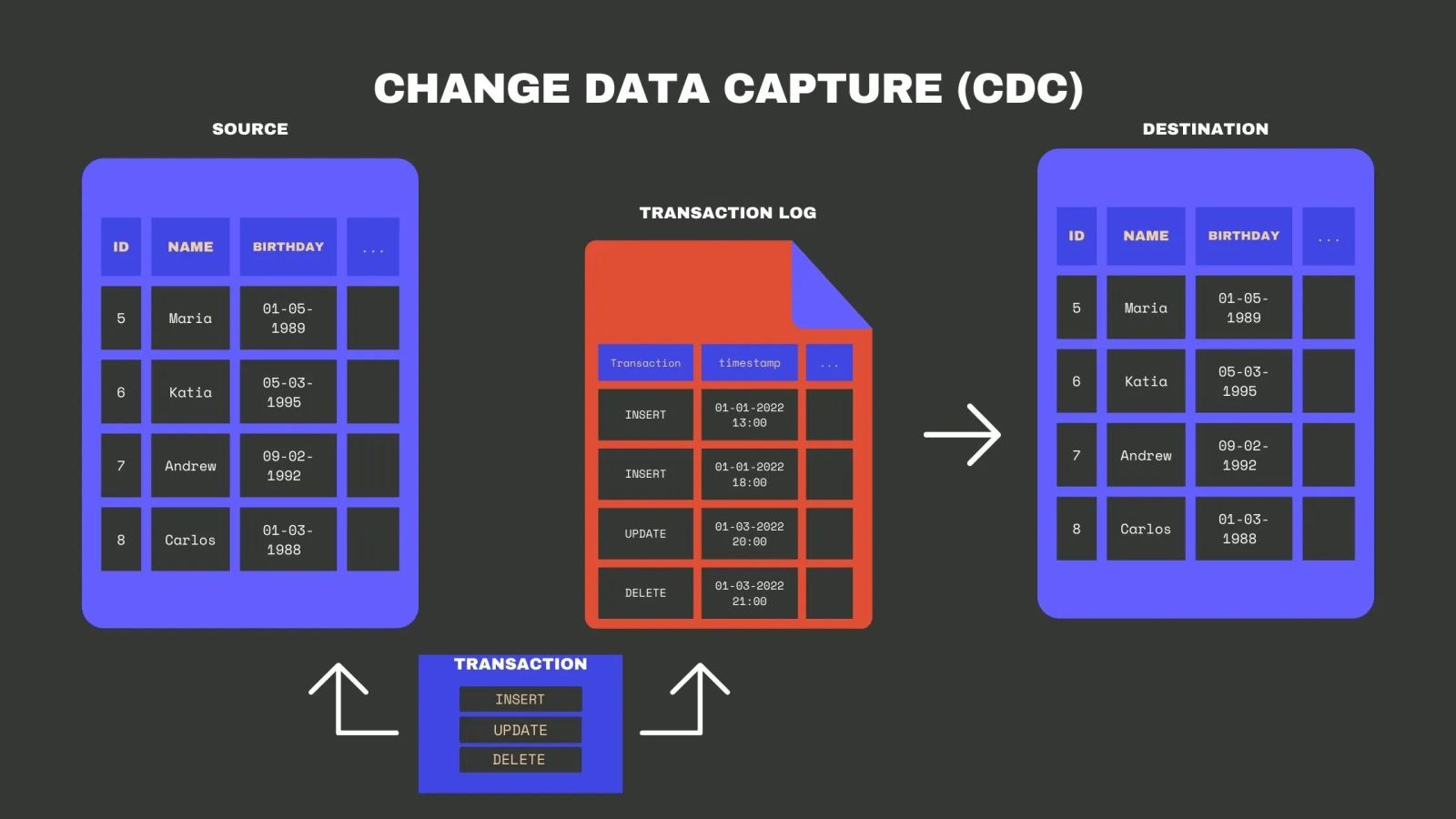
What is Change Data Capture? Change Data Capture is a software architecture that allows detecting and capturing changes made to data in a database and sending these changes, sometimes in real-time, to a downstream process or system. More specifically, CDC entails recording INSERT, UPDATE, and DELETE transactions applied to a table.
Capturing every change from a source database and moving it to a target – such as a data warehouse or data lake – helps keep systems in sync. Furthermore, because changes are captured with low latency, CDC enables near real-time analytics and data science.
Change Data Capture is also ideal for modern cloud architectures because it is a highly efficient way of moving data across a wide area network.
Change Data Capture vs. Batch processing Data replication is a process used to keep datastores in sync, which is often achieved using extract, transform, and load (ETL) pipelines. Since CDC concerns the extraction process, it can be used in ETL and ELT pipelines.
Traditionally, an ETL pipeline loads data into a database, data warehouse, or data lake in batches . With batch processing, the ETL is scheduled to be periodically executed (every hour or every day, for example). ETLs can replicate the full source database or only the new and updated data – these types of replication are called full replication and incremental replication , respectively.
But traditional batch processing has a few general drawbacks:
Data is not replicated in real-time. It can be inefficient, especially when performing full replication. It can overload the source database by regularly querying for new or updated data. It isn’t easy to track deletes in the source database when using incremental replication. How can CDC help overcome the issues above? To answer that, let’s look at the benefits that some CDC implementation methods can offer.
Change Data Capture benefits CDC is efficient Only data that has changed since the last replication is considered for a new sync when using Change Data Capture. This incremental design technique makes CDC substantially more efficient than alternative database replication patterns, such as full-database replication, which scans and copies the whole source database table with possibly millions of rows to the destination.
Check out our comprehensive article on Salesforce CDC to learn more about its transformative potential for your business!
CDC enables near real-time processing Some implementations, like log-based CDC, keep a transaction log updated as changes in the database happen – in real-time – so downstream systems can also be updated in near real-time , given a proper infrastructure. The former is impossible to achieve with batch processing, which is scheduled to run periodically.
Micro-batching is a technique that’s sometimes used to achieve near real-time replication, but it’s essentially different from CDC-based replication, and it doesn’t provide the same benefits.
CDC tracks delete operations in the source database An often-overlooked advantage of some CDC implementations is detecting deletes in the source database. Detecting deletes usually is difficult when using incremental batch processing because you’re essentially only looking at new or updated rows in the source tables. Since the CDC tracks delete operations , these can be easily propagated to the target.
CDC reduces the impact on the source database Some databases – like Postgres, MySQL, and SQL server – implement CDC natively, meaning that they keep a log of transactions as part of their core functionality. That means a process can read those CDC logs and identify and propagate the changes to the target without regularly querying the source database for changes. It is essential not to overload source databases, especially if they’re used in production systems.
Change Data Capture methods Various distinct Change Data Capture implementation methods have emerged throughout the years. However, not all CDC implementations are created equal, and you must select the appropriate method for your specific use case.
We discuss some of these CDC methods and the limitations associated with their use in the section below.
Table metadata This method keeps track of metadata across every row in a table, including when the row was created and updated. Using this method requires additional columns in the original table (such as created_at and updated_at ) or a separate table to track these different metadata elements.
Tracking metadata is commonly used in incremental batch processing to identify new and updated rows.
There are many ways to identify new and updated rows in the source table. The most common way is to look at the updated_at column in the destination table before replication to know the latest update and then identify the rows with a later updated_at in the source table. The result is the new and updated rows that should be merged at the destination.
A detailed implementation in Python for PostgreSQL CDC can be found here .
Key challenges:
If there are hard deletes in the source database, it’s impossible to track them using this method. Regularly querying the source database to identify new and updated rows can overload it. Table differences This method identifies the difference between the source and the destination tables to detect new, updated, and even deleted rows. The difference can be calculated using a SQL query or specific utilities provided by the database (for example, SQL Server provides a tablediff utility ).
Key challenges:
Comparing tables row-by-row to identify differences requires extensive computational resources, and it’s not scalable. Database triggers (Trigger-based CDC) This method requires the creation of database triggers with logic to manage the metadata within the same table or in a separate book-keeping table, often called a shadow table .
Most databases allow the creation of triggers; you can see how to create a trigger for PostgreSQL .
Key challenges:
If a transaction fails, roll-back logic may need to be implemented to remove the operation from the shadow table. The trigger needs to be modified in case of table schema changes. Triggers cannot be reused for other databases, given the differences in SQL language. The use of triggers can slow down the transactional workload. Database transaction log (Log-based CDC) Log-based CDC uses the transaction logs that some databases – such as Postgres, MySQL, SQL Server, and Oracle – implement natively as part of their core functionality.
Log-based and trigger-based CDC are very similar – both keep a log of changes every time a database operation happens – so the shadow table and the transaction log contain the same information. The difference between log-based and trigger-based CDC is that the first one uses a core functionality of the database (transaction log); meanwhile, the triggers are created and defined by the user.
Since database logs are updated in every transaction, the experience is transparent, which means log-based CDC does not require any logical changes in database objects or the application running on top of the database. A system reads data directly from the database Change Data Capture logs to identify changes in a database, minimizing the impact of the capture process.
Key challenges:
Some database operations are not captured in the CDC logs, such as ALTER or TRUNCATE. In that case, additional logic needs to be configured to force the logging of those operations. If the destination datastore is down, transaction logs must be kept intact until the subsequent replication happens. As you can see, there are several approaches to implementing Change Data Capture. Before databases included native CDC, data engineers used techniques such as table differences, table metadata, and database triggers to capture changes made to a database. These methods, however, can be inefficient and intrusive, and they tend to impose overhead on source databases.
As a result, many modern and real-time data architectures employ log-based CDC, which uses a background process to scan database transaction logs for changed data. Transactions are unaffected, and the impact on source databases is minimal. It’s also easy to implement, provided you have the right Change Data Capture tool.
Log-based CDC replication using Airbyte Until now, we have discussed what Change Data Capture is, different implementation methods, and why log-based CDC may be the best solution for production-level data replication. But, how can you efficiently use it in your data stack?
Even if the source database automatically creates a transaction log that you can readily use to replicate data, you still need to parse that log and load the changes to the target data warehouse or data lake. In other words, you need a consumer that understands the specific log syntax and propagates changes to the destination.
In addition, you may have more than one source database that you want to replicate using CDC, which means you need to create and maintain different consumers.
Does the above start to sound too complicated? Then, you may need to consider using a Change Data Capture tool and that’s where Airbyte can help. As the open-source data integration platform for modern data teams, Airbyte supports log-based CDC from Postgres , MySQL , and Microsoft SQL Server to any destination, such as BigQuery or Snowflake.
To support log-based CDC, Airbyte uses Debezium , an open-source platform that constantly monitors your databases, allowing your applications to stream database row-level changes. Airbyte is engineered to use Debezium as an embedded library, so you don’t need to worry about knowing its specifics.
Conclusion In this post, we defined what Change Data Capture is, how it works, and the benefits it can offer to a production data stack.
CDC is a data replication method with several advantages, especially if using log-based CDC. It’s one of the best approaches that data teams can use to enable near real-time analytics without compromising performance.
But even if implementing log-based CDC in your data stack comes with many benefits, it doesn’t mean that it’s easy. It requires data engineering knowledge and expertise. Fortunately, modern data integration platforms like Airbyte can help with the heavy lifting.
With Airbyte, you can create a log-based CDC pipeline without the need to parse logs or create and maintain logic for different consumers. This tutorial shows how straightforward it is to configure CDC for Postgres. If you’re ready to try it, you can deploy Airbyte open-source locally or on the cloud for free .
To explore more about data replication tools and their capabilities, check out our article on the top data replication tools available in the market.
Suggested Read
Snowflake CDC
CDC Tools