New: Airbyte Agents. Context-aware AI, built on your data.
Blog
/
Data
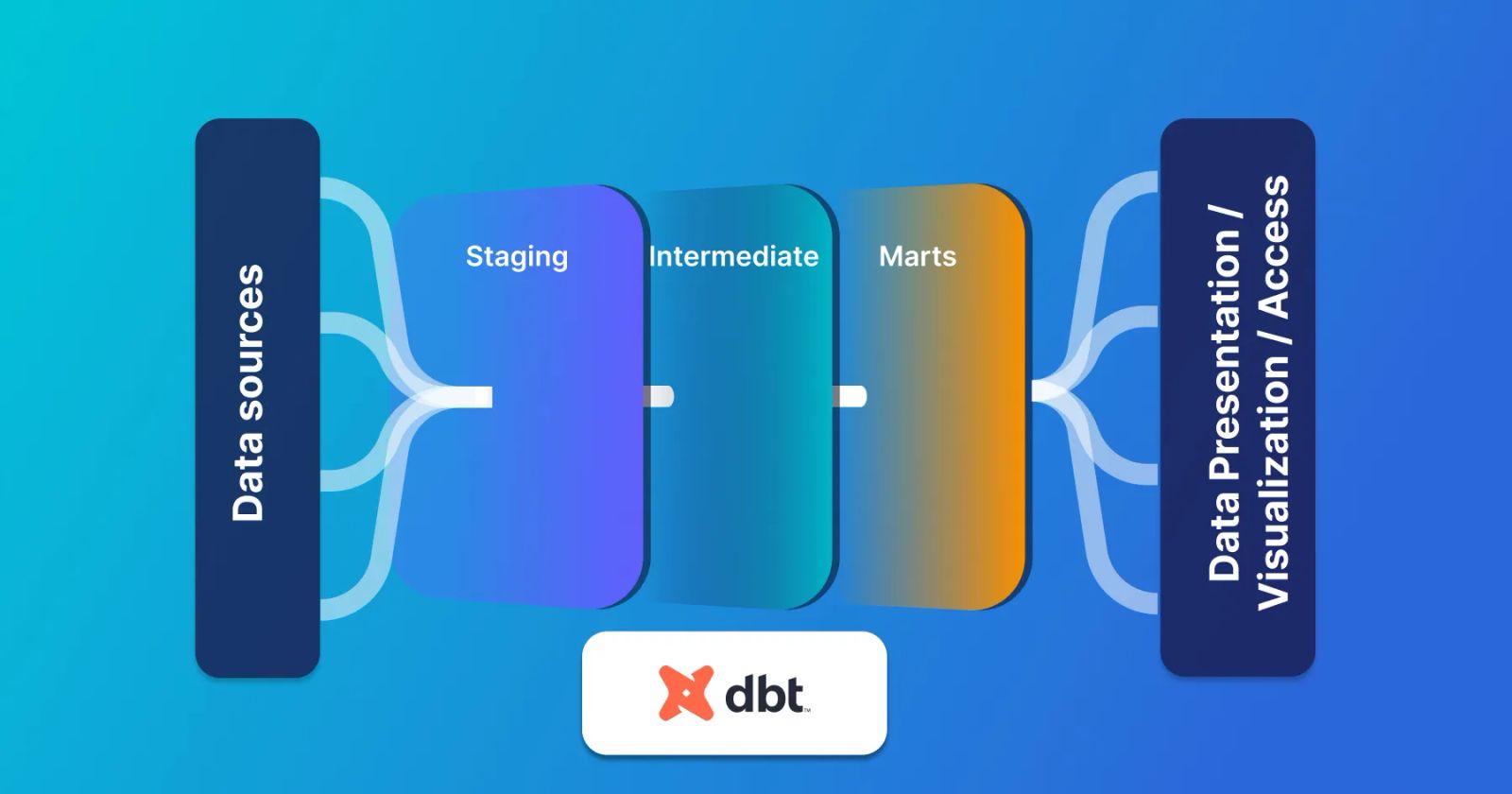
Craft high-quality data models using dbt from start to finish. Elevate your data architecture effortlessly.
Summarize with AI:
About the Author
Madison Schott
Madison Schott is an Analytics Engineer, author of The ABCs of Analytics Engineering book. Madison blogs about the modern data stack on Medium and writes a newsletter on Substack.
Be among the first to explore our new platform and get access to our latest features.
Join our newsletter to get all the insights on the data stack