Data Mesh Vs. Data Fabric Vs. Data Lake: Key Differences
Summarize this article with:

✨ AI Generated Summary
Businesses rely on data-driven insights for effective decision-making, so choosing the right framework or platform for data management is crucial. Among the most popular options are data mesh, data fabric, and data lakes.
Understanding the key differences between these options helps you optimize your data environment and align it with your operational requirements and objectives. This article compares data mesh vs data fabric vs data lake and outlines the benefits and drawbacks of each.
What Is a Data Mesh?
A data mesh is an architectural framework that decentralizes data ownership to business domains such as marketing, sales, and finance. The core principle is a distributed data model in which each domain manages its own data rather than relying on a centralized repository. This approach treats data as a product, ensuring enhanced ownership and accountability and leading to improved scalability, innovation, and collaboration.
Benefits of Data Mesh
- Domain-Oriented Ownership: A data mesh enables teams to manage the lifecycle of their own data, aligning data management with business needs and improving agility.
- High Scalability: A distributed architecture copes better with growing data volumes than centralized alternatives.
- AI-Driven Use Cases: Data mesh supports scalable machine learning and AI by providing granular, domain-specific datasets optimized for training and real-time decision-making applications.
Drawbacks of Data Mesh
- Effort-Intensive: Implementing a data mesh requires significant organizational change and planning.
- Data Migration Challenges: Moving data from lakes or monolithic warehouses to a mesh demands both technical and logistical preparation and a cross-functional approach to domain modeling.
- Coordination Complexity: Only a small percentage of organizations achieve the maturity required for successful decentralization, with interoperability challenges persisting due to overlapping domain boundaries.
What Is a Data Fabric?
A data fabric is a centralized data architecture that abstracts the complexities of data operations through a unified integration layer. It connects and manages data in real time across applications and systems, addressing challenges such as infrastructure complexity and data silos. Automated unification, cleansing, enrichment, and governance ensure data is ready for AI, ML, and analytics.
Benefits of Data Fabric
- Real-Time Analysis: Continuous data updates support real-time insights and performance optimization.
- Data Lineage: Built-in data lineage tracks origin, transformation, and movement, ensuring reliability and aiding decision-making.
- AI/ML Integration: Automated schema detection, anomaly correction, and predictive analytics streamline operations while reducing manual intervention requirements.
- Multi-Cloud Orchestration: Centralized APIs unify on-premise, cloud, and edge data, simplifying hybrid environments and reducing infrastructure complexity.
Drawbacks of Data Fabric
- Complexity: Implementing and managing a data fabric demands high technical expertise and can incur higher initial costs.
- Tool Integration Gaps: In some cases, data fabric may not integrate seamlessly with all existing platforms, reducing efficiency.
- Governance Overhead: While providing centralized control, fabric architectures can create bottlenecks when balancing central governance with domain autonomy requirements.
What Is a Data Lake?
A data lake is a centralized repository designed to store massive amounts of structured, semi-structured, and unstructured data in its raw format from transactional systems to social media and third-party apps. Modern data lakes are evolving into lakehouse architectures that blend structured and unstructured data capabilities with transaction control and schema evolution features.
Benefits of Data Lake
- High Scalability: Data lakes leverage distributed storage, scaling efficiently with growing volumes.
- Multi-Language Support: They support R, Python, SQL, Scala, and more, allowing analysts to use their preferred tools.
- Unified Metadata Management: Advanced lakes provide governance and security layers that centralize cataloging across both raw and processed data.
- Open Table Formats: Technologies like Apache Iceberg and Delta Lake enable vendor-agnostic interoperability and real-time analytics capabilities.
Drawbacks of Data Lake
- Complexity: Managing diverse data formats requires robust governance to keep data organized and usable.
- High Cost: Storage, management, and analysis at scale can become expensive.
- Data Swamp Risk: Without proper metadata management and governance frameworks, lakes can become unmanageable repositories that limit rather than enable analytics.
How Do Data Mesh, Data Fabric, and Data Lake Architectures Differ?
Data Mesh decentralizes data ownership by domain, Data Fabric provides an integrated layer for unified data access, and Data Lake stores raw, unstructured data at scale for diverse analytics.
Data Mesh
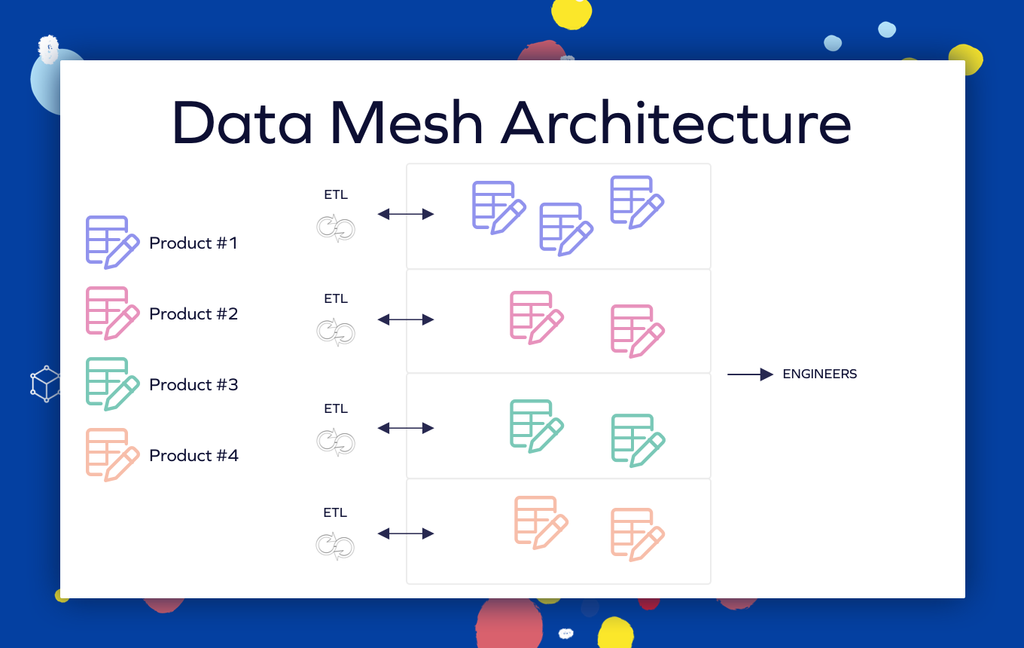
Four guiding principles:
- Distributed Domain-Driven Architecture
- Data as a Product
- Self-Serve Data Infrastructure
- Federated Data Governance
The data mesh approach emphasizes domain-specific pipelines where each business area ingests, processes, and publishes data as autonomous data products. For example, an e-commerce team might expose order events through a curated dataset with comprehensive metadata describing schema, SLAs, and usage guidelines.
Self-serve platforms provide centralized infrastructure tools like data catalogs and monitoring capabilities, enabling domain teams to focus on domain-specific logic rather than infrastructure management.
Data Fabric
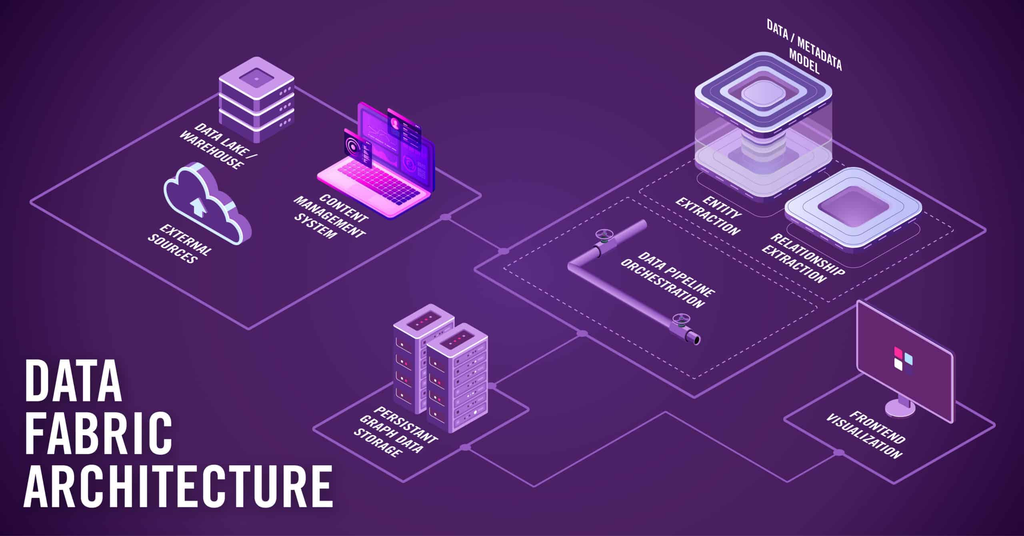
Key characteristics:
- Unified data access
- Seamless integration & orchestration
- Security, governance & compliance
- Scalability & flexibility
- Real-time insights and multi-cloud support
Data fabric architectures create unified data layers that integrate information from lakes, warehouses, databases, and SaaS tools through APIs, change data capture, and virtualization technologies. A practical example would be creating a 360-degree customer view that combines sales data from Salesforce, transaction logs from a data lake, and social media sentiment via APIs.
Data Lake
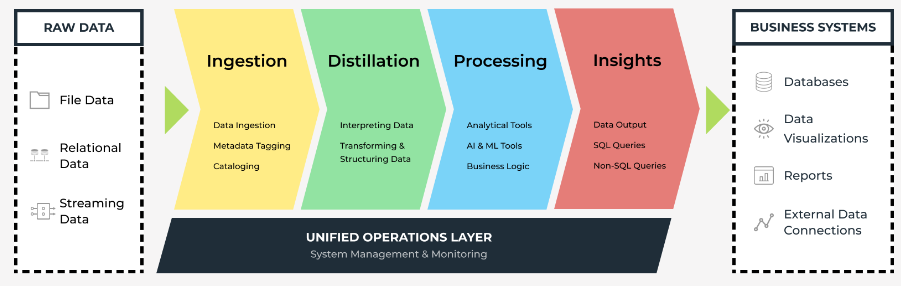
Layers:
- Ingestion
- Distillation
- Processing
- Insights
- Unified Operations
Modern data lake architectures implement ingestion-storage-consumption tiers that begin with batch and streaming tools capturing data from diverse sources. Object storage systems hold raw data globally, while processing engines like Spark and SQL engines such as Presto and Trino enable schema-on-read analysis.
How Do Data Access Patterns Differ Across These Architectures?
- Data Mesh: Each domain controls its own data while others access information via interoperable standards or shared APIs. This approach ensures data remains contextually aligned with business operations while enabling cross-domain collaboration through standardized interfaces. Domain teams assume full responsibility for data quality, accessibility, and consumer support, creating accountability aligned with business ownership.
- Data Fabric: Unified API gateways or central access layers offer a single cohesive view across all data sources and systems. Users interact with a consistent interface regardless of underlying data location or format, while the fabric handles routing, transformation, and security enforcement. This abstraction reduces complexity for data consumers while maintaining centralized governance and security controls.
- Data Lake: Central management interfaces, often catalog-driven, provide access to combined data repositories through metadata-driven discovery and query capabilities. Users typically interact with the lake through SQL engines, analytics platforms, or direct API access, with schema applied at query time rather than during ingestion. This approach maximizes flexibility for exploratory analytics while requiring users to understand data structures and quality characteristics.
What Are the Current Challenges in Modern Data Integration?
Modern data integration faces numerous challenges that traditional architectures struggle to address effectively:
Real-Time Processing and Streaming Failures
Many organizations still rely on batch processing for data integration, creating gaps in real-time decision-making capabilities. Streaming data pipelines frequently experience failures due to schema changes, data duplicates, or incomplete data capture. Traditional ETL tools struggle with event streams and time-critical IoT data, resulting in stale insights that limit competitive advantage.
Organizations can address these challenges by adopting event-driven architectures using platforms like Apache Kafka for low-latency data ingestion. Pairing these with change data capture tools enables real-time incremental data updates, while in-memory computation frameworks handle large-scale real-time processing for live dashboards and machine learning model training.
AI/ML Pipeline Integration Complexity
Machine learning models trained on static schemas break when data sources evolve, compromising reproducibility and model performance. Data lineage gaps in feature engineering pipelines hinder explainability requirements and complicate model retraining processes. These challenges become particularly acute as organizations scale their AI initiatives across multiple domains and use cases.
Solutions include embedding data contracts within ML workflows using schema registries to enforce consistent formats. Automated feature engineering pipelines with integrated data quality checks can flag drift in critical features, while platforms that combine data validation with ML workflows ensure model reliability and performance consistency.
Multi-Cloud Complexity and Vendor Lock-In
Data fragmentation across multiple cloud providers creates operational silos and increases management complexity. Hidden costs of moving data between providers can escalate budgets unexpectedly, while complex scripting requirements for cross-cloud orchestration create maintenance overhead and technical debt.
Cloud-agnostic abstraction layers help unify storage and compute across providers, while cost-aware architecture planning and monitoring tools optimize data placement to avoid expensive cross-region transfers. This approach enables organizations to leverage best-of-breed solutions without creating vendor dependencies.
Advanced Metadata Management Gaps
Current metadata management tools often focus on technical metadata like schemas and lineage, but lack contextual definitions that provide business meaning. Unstructured data, including images, audio, and natural language texts, frequently lacks consistent metadata tags, limiting searchability and governance effectiveness.
AI-driven metadata enrichment tools can parse unstructured data and automatically generate tags and relationships. Knowledge graphs built on graph databases map data relationships and enhance semantic search capabilities, providing context that improves data discovery and usage across organizations.
How Can Airbyte Efficiently Move Your Data into a Central Repository?
Airbyte is a modern data integration platform that simplifies data movement across diverse architectures, whether you're implementing data mesh, fabric, or lake strategies. As an open-source ELT platform, Airbyte consolidates data from disparate sources into your chosen destination while supporting the flexibility and governance requirements of modern data architectures.

Key features that support modern data architectures:
- 600+ Built-in Connectors: Extensive connector library eliminates custom development overhead for common integrations while supporting diverse data sources required across mesh domains, fabric integrations, and lake ingestion patterns.
- Custom Connector Development: The Connector Development Kit enables rapid creation of specialized connectors for unique business requirements, supporting the customization needs of domain-specific data products and enterprise integration scenarios.
- Real-Time Data Synchronization: Change Data Capture capabilities enable incremental syncs and real-time data movement, essential for streaming architectures and event-driven integration patterns.
- Developer-Friendly Tools: PyAirbyte open-source Python library enables data teams to build data-enabled applications quickly while maintaining integration with broader data infrastructure and governance frameworks.
- Enterprise-Grade Security: End-to-end encryption, role-based access control, and compliance capabilities support the governance requirements of fabric architectures while enabling the distributed security models needed for mesh implementations.
- Flexible Deployment Options: Support for cloud, hybrid, and on-premises deployments ensures Airbyte can integrate with any architectural approach while maintaining consistent functionality and management capabilities across environments.
What Factors Should Guide Your Architecture Choice?
Choosing between a data mesh, data fabric, and data lake depends on several key factors, including data volume, structure, budget, organizational maturity, and strategic objectives.
- Data Mesh works best for organizations with mature domain teams that require real-time domain-specific analytics and prioritize agility over centralization. Success factors include clear domain boundaries, robust interoperability standards, and strong platform engineering capabilities to support self-service infrastructure.
- Data Fabric suits enterprises needing unified data consistency across domains, relying on cross-domain analytics, or modernizing legacy systems. Success factors include strong central data teams, existing metadata infrastructure, and organizational culture that supports collaboration between centralized and domain-specific data operations.
- Data Lake fits organizations prioritizing cost-efficient big data storage, enabling machine learning experimentation, or prototyping new data workflows. Success factors include robust metadata management capabilities, data literacy across development and operations teams, and strict governance frameworks to prevent data swamp conditions.
Frequently Asked Questions
Does data mesh only handle analytical data?
No. While often associated with analytics use cases, data mesh architectures can effectively manage operational data as well. Domain teams can publish both analytical data products for business intelligence and operational data products that support real-time applications and business processes.
Are data fabric and data virtualization the same?
No. While both provide abstraction layers that simplify data access, they differ significantly in architecture and processing capabilities. Data virtualization focuses primarily on query-time data access without moving data, while data fabric encompasses broader integration, governance, and automation capabilities that may include physical data movement and transformation.
Can these architectures work together?
Yes. Many organizations successfully combine these approaches to leverage their respective strengths. For example, a data lake can serve as the storage foundation for data mesh domains, while data fabric tools can provide integration and governance capabilities across mesh implementations. These hybrid approaches often deliver better outcomes than single-architecture strategies.
How do I know which architecture is right for my organization?
The choice depends on your organizational maturity, technical capabilities, data governance requirements, and business objectives. Consider factors like team structure, data complexity, compliance requirements, and available technical resources. Many organizations benefit from starting with one approach and gradually incorporating elements from others as their capabilities and needs evolve.
What role does cloud architecture play in these decisions?
Cloud capabilities significantly influence architectural choices. Multi-cloud strategies often favor data fabric approaches for unified management, while cloud-native organizations may find data mesh aligns with microservices architectures. Data lakes benefit from cloud storage economics and scalability, but governance becomes more complex in distributed cloud environments.
.webp)