Data Mapping in ETL: What it is & How it Works?
Learn how data mapping works in ETL processes, best practices for implementation, and techniques for efficient data integration.

With the rapid growth of data production, organizations increasingly rely on data integration to unify information from multiple sources for analytics and decision-making. As a result, the data integration market continues to expand as businesses seek efficient ways to manage and analyze growing volumes of data.
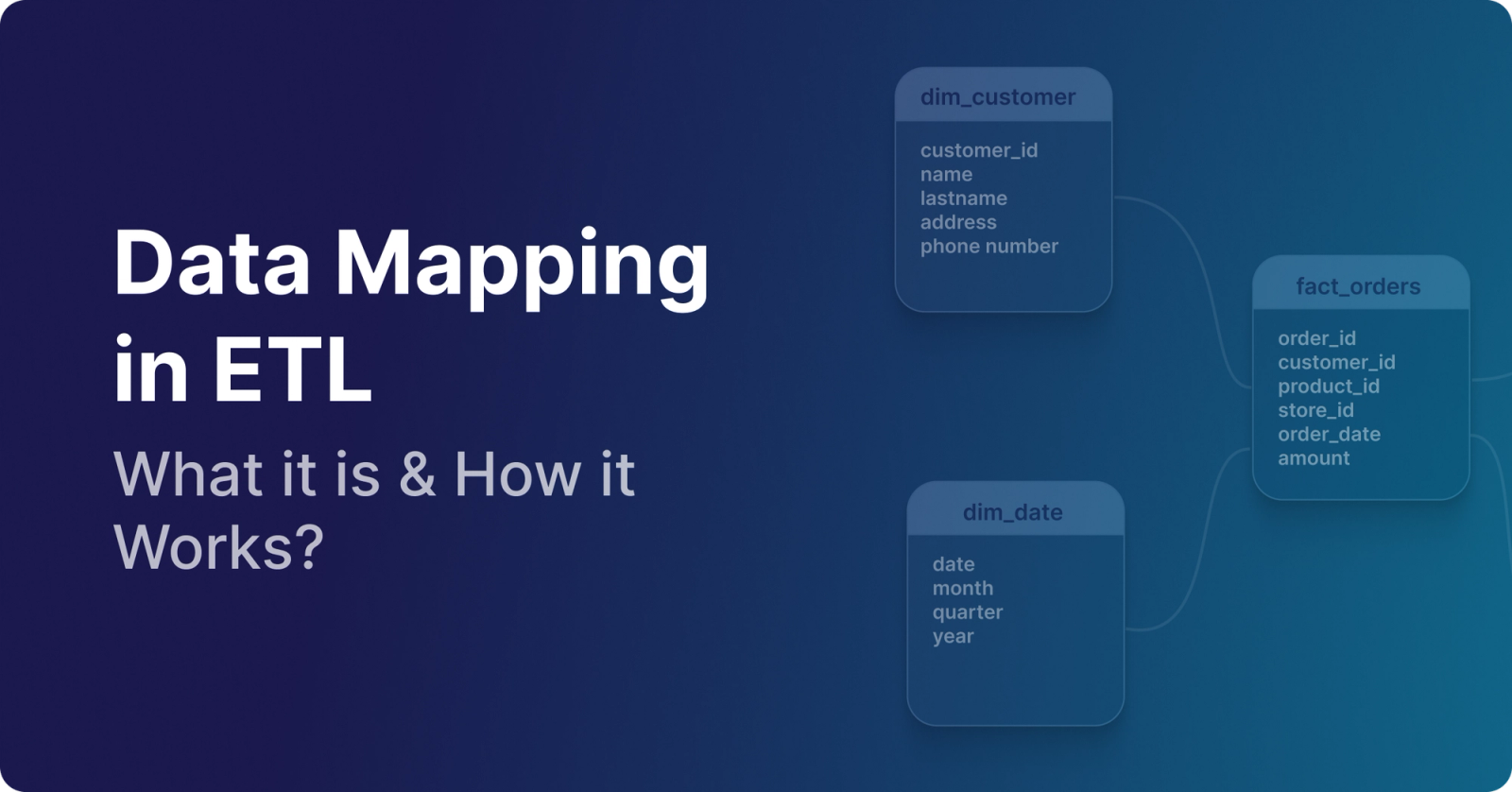
Data mapping in ETL is the process of linking fields from source systems to corresponding fields in a destination system to ensure data is transformed into a consistent and usable format. It plays a critical role in both ETL and ELT pipelines by enabling standardized data that supports accurate analytics, reporting, and governance.
In this guide, you'll learn what data mapping in ETL is, how it works, its core components, and the different types of data mapping used in modern data integration environments. We’ll also explore how modern approaches incorporate automation, artificial intelligence, and real-time processing to handle complex enterprise data integration workflows.
What Is Data Mapping in ETL?
Data mapping in ETL is the process of matching related data fields across two or more source databases before consolidating them into a destination. By mapping data, you can identify relationships between diverse data records and transform them to get a consistent dataset. Such a dataset is essential for accurate analytics and business operations.
Modern data mapping has evolved to handle not only structured database fields but also semi-structured and unstructured data formats, enabling more comprehensive data integration scenarios. Contemporary data mapping approaches leverage advanced algorithms and machine learning techniques to automate field relationship detection, reducing manual effort while improving accuracy.
These intelligent systems can recognize semantic relationships between fields that have different names but similar meanings. For example, they can understand that "customer birth date" and "date of birth" represent the same conceptual data element.
For example, when mapping data from an SQL source to a destination system, you might rename customer_id to source_id to match the destination schema. You could also merge first_name, middle_name, and last_name as full_name in the target system.
Modern mapping systems can handle these transformations automatically through pattern recognition and learned behaviors from previous mapping configurations. This significantly reduces the time and expertise required for complex data integration projects.
Where Does Data Mapping Fit in the ETL Process?
The ETL data integration technique involves the extraction of data from various sources. You can then transform and load this data to a suitable destination. Here, the role of data mapping comes into play during transformation.
However, modern approaches increasingly implement mapping logic throughout the entire ETL pipeline. Some mapping decisions occur during extraction phases while others are deferred until loading phases.
During data mapping, you match the data source elements to corresponding fields in the destination. You can also set transformation rules to modify source data records before loading. Advanced mapping systems now support dynamic mapping configurations that can adapt to schema changes without manual intervention, ensuring data integration processes remain resilient as source systems evolve.
To implement effective ETL data integration, you can opt for semantic mapping that involves finding contextual similarity between differently represented data records in source and destination systems. For example, a field named birth_date in the source may be mapped to dob in the destination. Semantic mapping has advanced significantly with the integration of natural language processing and machine learning, enabling systems to understand context and meaning rather than relying solely on exact field name matches.
What Are the Core Components of ETL Data Mapping?
ETL data mapping consists of several core components that work together to ensure successful data integration:
1. Source Elements
The source elements include the fields that you have extracted from source data systems. Before mapping, you should properly examine these data elements to understand their structure, data type, and format. Modern data profiling techniques automate this examination process, providing comprehensive analysis of data patterns, quality characteristics, and relationship structures that inform mapping decisions.
2. Target Elements
Target data elements are the fields in the destinations, such as data warehouses, cloud storage solutions, BI tools, or data lakes. Understanding these elements allows you to prepare a strategy for data mapping in advance. Contemporary target element analysis incorporates schema evolution capabilities that automatically adjust to changes in destination systems while maintaining data integrity and consistency.
3. Mapping Rules
Mapping rules are the set of guidelines that you must follow to transform source data records to match target data fields. These guidelines include formatting rules, data type conversions, and renaming criteria. Advanced mapping rule engines now support complex conditional logic, business rule validation, and dynamic rule application based on data characteristics and processing context.
4. Transformation Logic
Transformation logic involves data enrichment, filtering, and cleaning techniques. These methods assure accurate and credible data mapping. Modern transformation logic has evolved to include sophisticated data quality validation, automated anomaly detection, and intelligent data enrichment that can enhance datasets with contextual information from external sources.
Why Is Data Mapping Important in ETL?
Data mapping can enhance the operational efficiency of your organization in several ways:
1. Better Data Quality
Data mapping helps you tune datasets by aligning the fields, formats, and different types of data records across multiple databases. Through this, you can eliminate discrepancies between data points stored in different sources. Data mapping also allows you to transform data correctly by merging duplicates and removing missing values.
2. Effective Data Analysis
ETL data mapping allows you to achieve a clean and well-integrated dataset. Such a data store helps you in generating meaningful analytical insights and in training machine learning models for enhanced predictive analytics.
4. Robust Data Governance
Effective data governance requires a unified and complete dataset. ETL data integration and proper mapping can help you achieve this by making it easy to track data lineage and apply security controls such as masking for sensitive fields.
5. Cost Management
Data mapping significantly reduces errors in data workflows, saving the cost of reworking. It allows you to integrate only relevant data, reducing the cost of investment in unnecessary computational resources.
What Are the Different Types of Data Mapping?
There are three main types of data mapping, each offering distinct advantages:
1. Manual Data Mapping
You write code or use drag-and-drop interfaces to link and understand relationships between data records. This approach is favorable for one-time data transfers or small datasets.
2. Automated Data Mapping
Automated tools manage the mapping process end-to-end, using techniques such as rule-based logic, machine learning, and AI to identify how to map source and target fields. Some popular data mapping tools fall into this category.
3. Semi-Automated Data Mapping
A hybrid approach that combines automation with manual oversight. Tools detect schemas and suggest mappings, while users review and customize the results.
How Does ETL Data Mapping Work?
Step 1: Recognize the Source Data Elements
Identify the data elements you want to extract. Sources can include databases, flat files, data warehouses, or data lakes.
Step 2: Develop a Plan to Map Your Data
Create a detailed data map aligning source data points with the destination. Define mapping rules and transformation logic.
Step 3: Test
Validate mapping rules with data-type checks, format checks, uniqueness checks, and performance benchmarks.
Step 4: Data Migration
Apply mapping rules and migrate the standardized data to the destination system.
Step 5: Monitor
Continuously monitor both source and destination systems. Update mapping rules as source schemas evolve.
How Can AI-Driven Automated Data Mapping Transform Your Integration Process?
AI and machine learning introduce intelligent automation that can reduce manual effort, improve accuracy, and adapt to change. Key innovations include:
1. Semantic Intelligence and Pattern Recognition
Understanding field meaning beyond simple name matching.
2. Machine Learning-Enhanced Transformation Logic
Learning from historical pipelines to suggest optimal transformations.
How Do Real-Time Streaming ETL and Event-Driven Integration Change Data Mapping?
1. Event-Driven Architecture and Change Data Capture (CDC)
Real-time capture and processing of source changes allows for immediate data synchronization.
2. Continuous Data Flow and Schema Evolution
Mapping systems must adapt dynamically without interrupting data streams to maintain continuous operations.
What Should You Know About Airbyte's Modern Data Integration Capabilities?
Airbyte offers comprehensive data integration solutions that address modern ETL data mapping challenges:
Airbyte provides 600+ pre-built connectors and an AI-powered connector builder for rapid integration development. The platform includes enterprise-grade security features, including SOC 2 Type II and ISO 27001 compliance.
The platform supports vector database connectors for Pinecone, Milvus, and Weaviate to handle AI/ML workloads. Airbyte offers self-managed and multi-region support for compliance-sensitive deployments.
These capabilities enable organizations to implement sophisticated ETL data mapping strategies while maintaining security and governance requirements. The platform's flexibility supports both cloud-native and on-premises deployment models.
Conclusion
ETL data mapping represents a fundamental component of modern data integration strategies. As organizations continue to generate increasing volumes of data from diverse sources, effective mapping becomes critical for maintaining data quality and enabling meaningful analytics.
Modern mapping approaches that incorporate AI, real-time processing, and automated intelligence provide unprecedented opportunities for organizations to streamline their data integration processes. The evolution of ETL data mapping continues to transform how enterprises approach data consolidation and transformation challenges.
Frequently Asked Questions
1. How do I handle data quality issues during the mapping process?
Implement automated profiling, machine-learning-aided anomaly detection, and real-time monitoring to catch issues early.
2. What are the best practices for handling schema changes in ETL mapping?
Use automated schema detection, versioning, and flexible schema-on-read designs to minimize disruptions.
3. How do I optimize ETL mapping performance for large datasets?
Adopt parallel processing, intelligent caching, and in-memory techniques while monitoring key performance metrics.
4. How can I ensure security and compliance in my ETL mapping processes?
Apply end-to-end encryption, role-based access controls, sensitive data detection, and detailed audit logging.
5. What monitoring and maintenance practices should I implement for ETL mapping?
Maintain real-time dashboards, automated alerts, complete data lineage tracking, and predictive maintenance routines.
Suggested Read:
Integrate with 600+ apps using Airbyte
Move data from 600+ sources into warehouses, lakes, and beyond. Set up pipelines in minutes with pre-built connectors and the Connector Builder.