New: Airbyte Agents. Context-aware AI, built on your data.
Dive into the ADA Stack with BigQuery quickstart guide! Discover how to harness Airbyte, dbt, and Apache Airflow for a streamlined ELT pipeline, complete with practical examples to kickstart your project.
Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.



Welcome to the Airbyte, dbt and Airflow (ADA) Stack with BigQuery quickstart! This repo contains the code to show how to utilize Airbyte and dbt for data extraction and transformation, and implement Apache Airflow to orchestrate the data workflows, providing a end-to-end ELT pipeline. With this setup, you can pull fake e-commerce data, put it into BigQuery, and play around with it using dbt and Airflow.
Here's the diagram of the end to end data pipeline you will build, from the Airflow DAG Graph view:
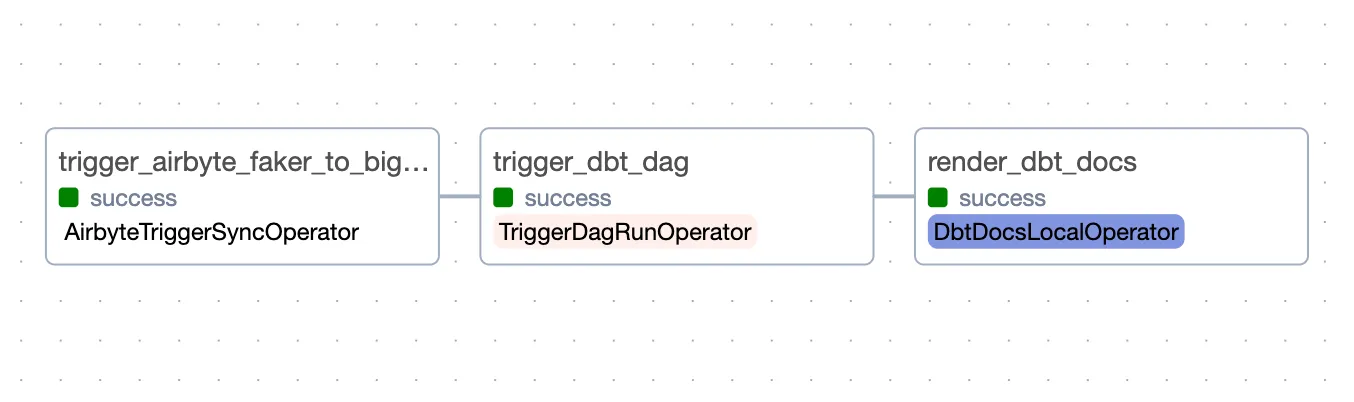
And here are the transformations happening when the dbt DAG is executed:
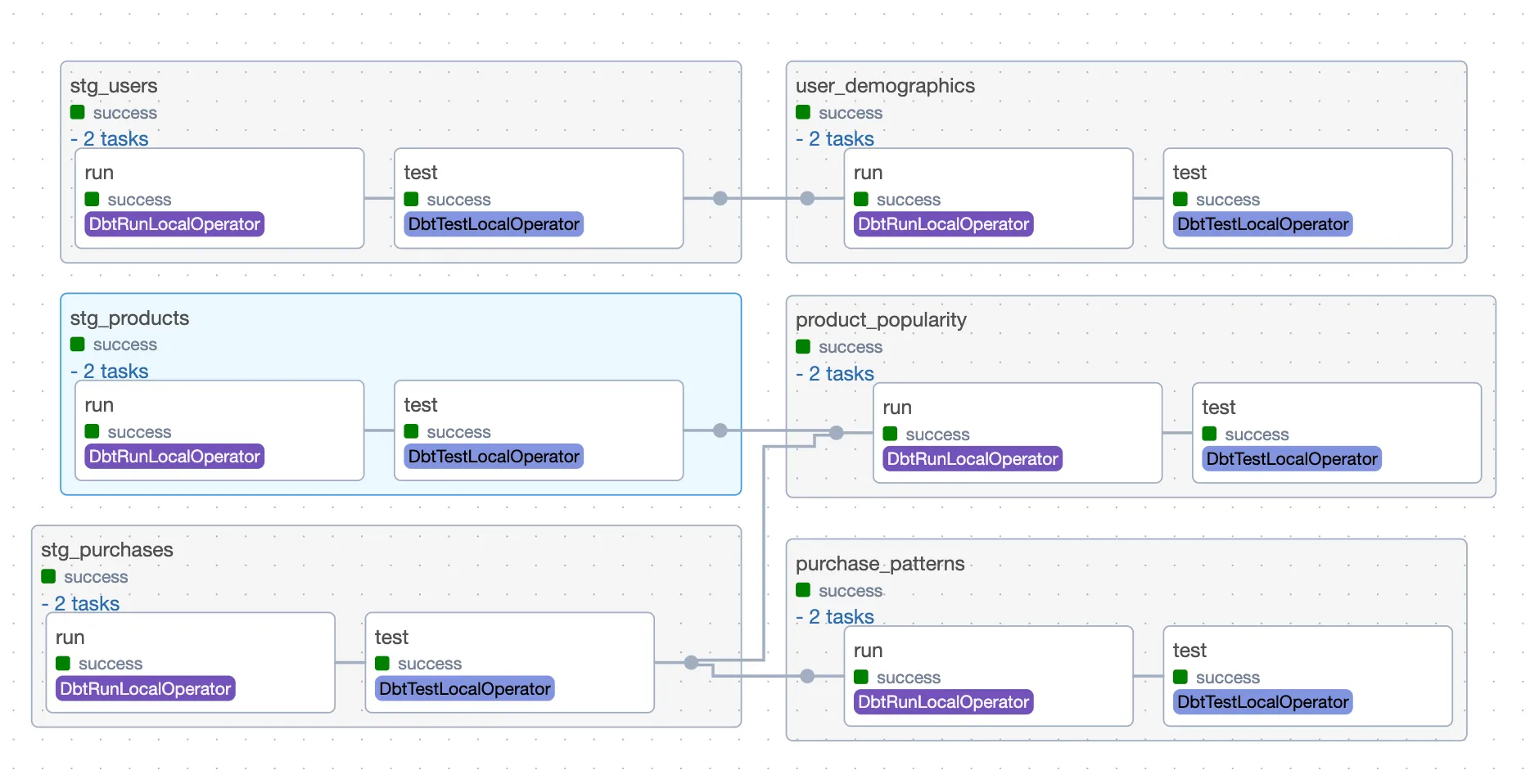
Before you embark on this integration, ensure you have the following set up and ready:
Get the project up and running on your local machine by following these steps:
At this point you can view the code in your preferred IDE.
The next steps are only necessary if want to develop or test the dbt models locally, since Airbyte and Airflow are running on Docker.
You can use the following commands, just make sure to adapt to your specific python installation.
For Linux and Mac:
For Windows:
If you have a Google Cloud project, you can skip this step.
If you pick different names, remember to change the names in the code too.
The key will download automatically. Keep it safe and don’t share it.
To set up your Airbyte connectors, you can choose to do it via Terraform, or the UI. Choose one of the two following options.
Airbyte allows you to create connectors for sources and destinations via Terraform, facilitating data synchronization between various platforms. Here's how you can set this up:
1. Navigate to the Airbyte Configuration Directory:
2. Modify Configuration Files:
Within the <span class="text-style-code">infra/airbyte</span> directory, you'll find three crucial Terraform files:
Adjust the configurations in these files to suit your project's needs by providing credentials for your BigQuery connection in the <span class="text-style-code">main.tf</span> file:
Alternatively, you can utilize the <span class="text-style-code">variables.tf</span> file to manage these credentials. You’ll be prompted to enter the credentials when you execute terraform plan and terraform apply. If going for this option, just move to the next step. If you don’t want to use variables, remove them from the file.
3. Initialize Terraform:
This step prepares Terraform to create the resources defined in your configuration files.
4. Review the Plan:
Before applying any changes, review the plan to understand what Terraform will do.
5. Apply Configuration:
After reviewing and confirming the plan, apply the Terraform configurations to create the necessary Airbyte resources.
6. Verify in Airbyte UI:
Once Terraform completes its tasks, navigate to the Airbyte UI. Here, you should see your source and destination connectors, as well as the connection between them, set up and ready to go 🎉.
Start by launching the Airbyte UI by going to http://localhost:8000/ in your browser. Then:
1. Create a source:
2. Create a destination:
3. Create a connection:
That’s it! Your connection is set up and ready to go! 🎉
dbt (data build tool) allows you to transform your data by writing, documenting, and executing SQL workflows. Setting up the dbt project requires specifying connection details for your data platform, in this case, BigQuery. Here’s a step-by-step guide to help you set this up:
Move to the directory containing the dbt configuration:
You'll find a <span class="text-style-code">profiles.yml</span> file within the directory. This file contains configurations for dbt to connect with your data platform.
You can test the connection to your BigQuery instance using the following command. Just take into account that you would need to provide the local path to your service account key file instead:
If everything is set up correctly, this command should report a successful connection to BigQuery 🎉.
Let's set up Airflow for our project, following the steps below. We are basing our setup on the Running Airflow in Docker guide, with some customizations:
Open the <span class="text-style-code">.env.example</span> file located in the orchestration directory.
Update the necessary fields, paying special attention to the <span class="text-style-code">GCP_SERVICE_ACCOUNT_PATH</span>, which should point to your local service account JSON key directory path.
Rename the file from <span class="text-style-code">.env.example</span> to <span class="text-style-code">.env</span> after filling in the details.
This might take a few minutes initially as it sets up necessary databases and metadata.
Both for using Airbyte and dbt, we need to set up connections in Airflow:
Click on the + button to create a new connection and fill in the following details to create an Airbyte connection:
Click on the "Test" button, and make sure you get a "Connection successfully tested" message at the top. Then, you can save the connection.
Click on the + button to create a new connection and fill in the following details to create an Google Cloud connection:
Click on the "Test" button, and make sure you get a "Connection successfully tested" message at the top. Then, you can save the connection.
We use Astronomer Cosmos to integrate dbt with Airflow. This library parses DAGs and Task Groups from dbt models, and allows us to use Airflow connections instead of dbt profiles. Additionally, it runs tests automatically after each model is completed. To set it up, we've created the file <span class="text-style-code">orchestration/airflow/config/dbt_config.py</span> with the necessary configurations.
Update the following in the <span class="text-style-code">dbt_config.py</span> file, if necessary:
The last step being being able to execute the DAG in Airflow, is to include the connection ID from Airbyte:
That's it! Airflow has been configured to work with dbt and Airbyte. 🎉
Now that everything is set up, it's time to run your data pipeline!
This will initiate the complete data pipeline, starting with the Airbyte sync from Faker to BigQuery, followed by dbt transforming the raw data into staging and marts models. As the last step, it generates dbt docs.
Congratulations! You've successfully run an end-to-end workflow with Airflow, dbt and Airbyte. 🎉
Once you've gone through the steps above, you should have a working Airbyte, dbt and Airflow (ADA) Stack with BigQuery. You can use this as a starting point for your project, and adapt it to your needs. There are lots of things you can do beyond this point, and these tools are evolving fast and adding new features almost every week. Here are some ideas to continue your project:
This quickstart uses a very simple data source. Airbyte provides hundreds of sources that might be integrated into your pipeline. And besides configuring and orchestrating them, don't forget to add them as sources in your dbt project. This will make sure you have a lineage graph like the one we showed in the beginning of this document.
dbt is a very powerful tool, and it has lots of features that can help you improve your transformations. You can find more details in the dbt Documentation. It's very important that you understand the types of materializations and incremental models, as well as understanding the models, sources, metrics and everything else that dbt provides.
dbt provides a simple test framework that is a good starting point, but there is a lot more you can do to ensure your data is correct. You can use Airflow to run manual data quality checks, by using Sensors or operators that run custom queries. You can also use specialized tools such as Great Expectations to create more complex data quality checks.
Airflow's UI is a good start for simple monitoring, but as your pipelines scale it might be useful to have a more robust monitoring solution. You can use tools such as Prometheus and Grafana to create dashboards and alerts for your pipelines, but you can create notifications using Airflow or other tools such as re_data.
All tools mentioned here are open-source and have very active communities. You can contribute with them by creating issues, suggesting features, or even creating pull requests. You can also contribute with the Airbyte community by creating connectors for new sources and destinations.
Download our free guide and discover the best approach for your needs, whether it's building your ELT solution in-house or opting for Airbyte Open Source or Airbyte Cloud.

