In case you missed Part 1, An Introduction to Data Modeling , make sure to check first, where we discussed the importance of data modeling in data engineering, the history, and the increasing complexity of data. We have also touched upon the significance of understanding the data landscape, its challenges, and much more.
As we delve deeper into this topic, Part 2 will focus on data modeling approaches and techniques. These methods play a vital role in effectively designing and structuring data models, allowing organizations to gain valuable insights from their data.
We will discuss various data modeling approaches, such as top-down and bottom-up, and specific data modeling techniques, like dimensional modeling, data vault modeling, and more. We will address the common challenges faced in data modeling and how to mitigate them. By understanding these approaches and techniques, data engineers can better navigate the complexities of data modeling and design systems that cater to their organization's specific needs and goals.
Data Modeling Approaches When designing your data model, you typically begin with a top-down approach. You sit with your business owners and domain experts and ask them questions to understand what entities your organization will implement, e.g., customer, product, and sales. Bottom-up is the alternative, where you go from a physical data model. We'll discuss it in a minute.
Agreeing on how you visualized your data flow, and your data is essential to brainstorm up front between domain experts and the data engineering, business intelligence, or analytics engineer involved. It will help you design it in steps, avoid siloed modeling by engineers only, and define familiar entities used company-wide.
It also helps and should be done to define KPIs and Metrics upfront. These are agreed-upon goals you want to achieve together. As a data modeler, here is where you get the dimensions you need and the fact granularity . E.g., are we talking monthly, weekly, or daily revenue numbers? Are these plotted on a map per city or country?
The challenge of data modeling is Data Literacy . Data literacy is the ability to derive meaningful information from data, just as literacy, in general, is the ability to derive information from the written word—or, said differently, extrapolating the business value from the data given. Let's figure out how to mitigate those problems with processes and techniques.
⚠️ Terminology is important. It's essential to get the Terminology right so that everyone understands what the customer is, or if not, you need to be more specific and say oss_customer and enterprise_customer, for example. We don't need to reinvent these entities; there are many reference models you can borrow from. Conceptual, Logical, and Physical Data Models Let's start with the Conceptual Data Model represents a high-level view (top-down), the logical data model provides a more detailed representation of data relationships, and the physical data model defines the actual implementation in the database or data storage system (bottom-up)—more on the top and bottom-up approaches in the following chapters.
The Conceptual, Logical, and Physical Data Modeling Flow A common approach is to start with the conceptual model, where you define the entities in your organization from a top-down and high-level perspective and model them together. Usually, the Entity Relationship Diagram (ERD) is used for this.
Later, you move to a logical model where you add more details, such as the ID, whether you create a PK or use the business key from the source system. Are you modeling the customer as normalized tables (customer, address, geographic), or do you keep it simple with duplications? How do you implement change history of data; are you using Slowly Changing Dimension (Type 2) or snapshotting all dimensions?
The physical model is where you implement or generate it to the destination database system respecting each database's slightly different syntax.
Simple flow from conceptual to the physical data model. The Benefit of a conceptual model in a larger enterprise organization of sufficient complexity has a conceptual data model gives you a great framework to order the logical and physical models around, decoupled from the source systems .
🙋🏼♀️ The Logical Layer == Semantic Layer? As a Semantic Layer is essentially a logical business layer, it must be considered using one during the model part. More on this in Part 3 . Conceptual Data Model: Top-Down Approach In a top-down approach, you start with a high-level view of the organization's data requirements. This involves working with business owners, domain experts, and other stakeholders to understand the business needs and create a conceptual data model.
Then, you iteratively refine the model, moving from conceptual to logical and finally to the physical data model. This approach is particularly suitable when there is a clear understanding of the business requirements and goals .
Physical Data Model: Bottom-Up Approach On the other hand, the bottom-up approach begins with analyzing the existing data sources, such as databases, spreadsheets, or different structured and unstructured data. Based on this analysis, you create a physical data model that reflects the current data storage and relationships.
Next, you work your way up, creating a logical data model to represent the business requirements and a conceptual model to provide a high-level view of the data. The bottom-up approach is beneficial when dealing with legacy systems or when there needs to be more knowledge of the organization's data requirements.
Combining top-down and bottom-up approaches in data modeling Combining top-down and bottom-up approaches may be the best solution in many cases. By blending these methods, you can capitalize on the strengths of each approach and create a comprehensive data model that meets your organization's needs.
Regardless of your chosen approach, it's essential to maintain clear communication among all stakeholders and ensure that the data model aligns with the organization's objectives and supports effective decision-making.
Hierarchical Data Modeling, Network Data Modeling and Object-Role Modeling? While searching for other approaches, I came across hierarchical, network, and object-oriented data modeling.
Different Data Models | Image from Wikipedia The hierarchical data modeling organizes data in a tree-like structure, with parent-child relationships between entities. It is suitable for representing hierarchical data or nested relationships, such as organizational structures or file systems.
The network data modeling approach models data as interconnected nodes in a graph, allowing for complex relationships between entities. It helps represent many-to-many relationships and networks, such as social networks, transportation networks, or recommendation systems.
The object-role modeling is an attribute-free, fact-based data modeling method that ensures a correct system and enables the derivation of ERD, UML, and semantic models while inherently achieving database normalization.
Some more , such as the flat model, object–relational model, are listed on Wikipedia for data models.
Data Modeling Techniques In Part 1 , we introduced the various levels of data modeling, including generation or source database design, data integration, ETL processes, data warehouse schema creation, data lake structuring, BI tool presentation layer design, and machine learning or AI feature engineering. We also discussed different approaches to data modeling in the previous chapter. This chapter will delve deeper into the practical techniques used in the data modeling process.
These techniques are primarily employed in batch-related processes and cater to the design and modeling of Data Warehouses , Lakes , or Lakehouses . We will explore each technique’s unique benefits and applications in modern data engineering.
Dimensional Modeling There are many different techniques, but Dimensional Modeling is probably the most famous and the one that has stood out the longest. Its birth was with the inception of the data warehouse and the release of the iconic The Datawarehouse Toolkit book in a 1996 book.
The History of the Data Warehouse Toolkit book in Perspective to Cloud Data Warehouse | Image by Josh and Sydney from above mentioned talk about Babies and bathwater The data space has changed a lot since then, so the question arises, “Is dimensional modeling still needed within data engineering compared to its popularity way back?” Let’s find out in the following chapters.
A quick reminder of how data modeling looked for a long time:
The retail sales star schema, example from Kimball | Image by Research Gate. Data Modeling vs. Dimensional Modeling Let’s start with the difference between dimensional and data modeling to understand why we even discuss it.
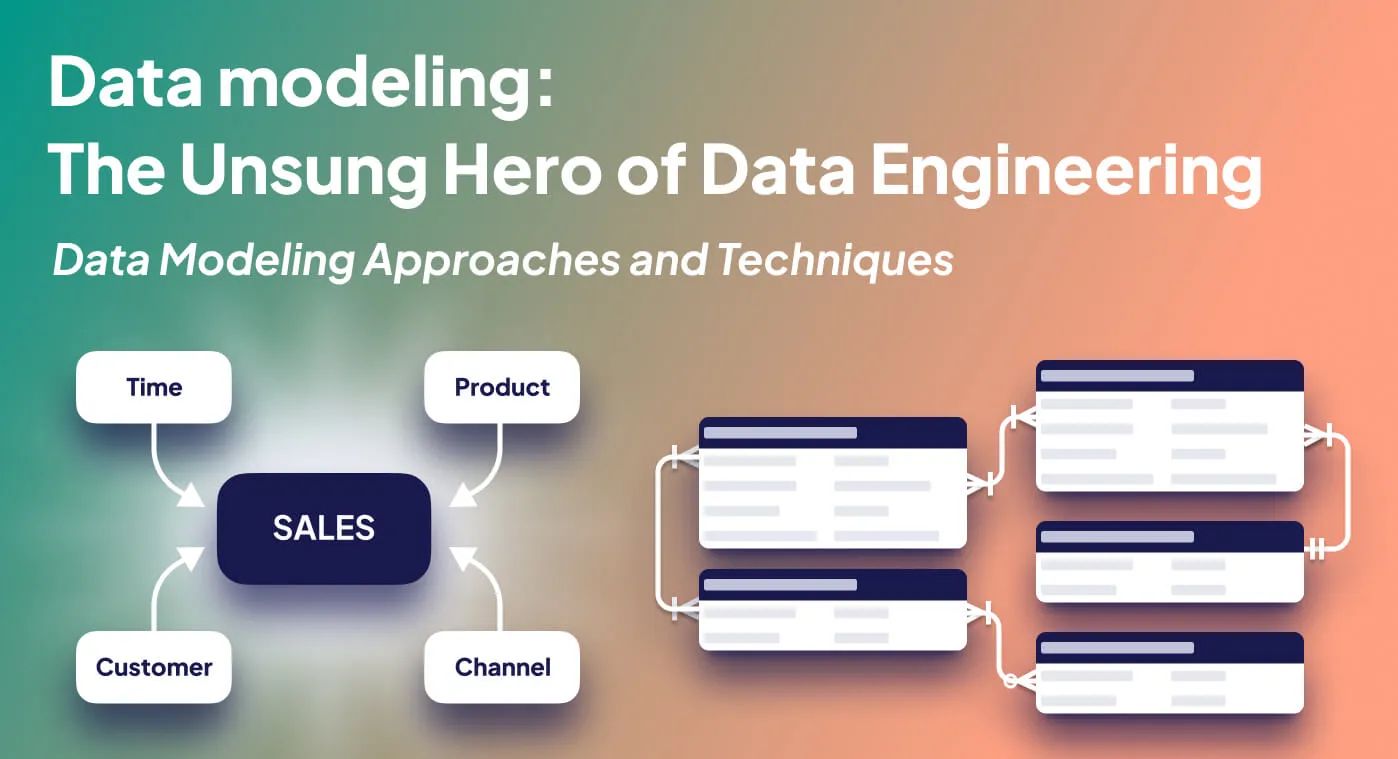
Data modeling is the broad term that encompasses various techniques and methodologies for representing and modeling data across a company.Dimensional modeling is a specific approach to data modeling that is particularly suited for data warehousing, business intelligence (BI) applications, and newer data engineering data models.What is Dimensional Modeling So what, then, is dimensional modeling? Dimensional modeling focuses on creating a simplified, intuitive structure for data by organizing data into facts and dimensions , making it easier for end-users to query and analyze the data.
In dimensional modeling, data is typically stored in a star schema or snowflake schema (more later), where a central fact table contains the quantitative data, and it is connected to multiple dimension tables, each representing a specific aspect of the data’s context. This structure enables efficient querying and aggregation of data for analytical purposes.
👉🏻 Context on Facts and Dimensions Facts represent quantitative or measurable data (e.g., sales, revenue, etc.) and dimensions represent the context or descriptive attributes (e.g., customer, product, time, etc.). The dimensional modeling approach focuses on identifying the key business entities and modeling these in an easy-to-understand way for consumers.
With the DW/BI Lifecycle Methodology that was created later in the 90s, Kimball’s core ideas applying still to this very day which is:
Focus on adding business value across the enterprise. Dimensionally structure the data that are delivered to the business.Iteratively develop in manageable lifecycle increments rather than attempting a Big Bang approach. Key concepts of dimensional modeling could be an article, and so much content exists. I leave you here with some links to learn more. For example, around dimensions with Conformed Dimensions , Junk Dimension or Slowly Changing Dimension , Additive, semi-additive, and non-additive facts , and many more; check out Dimensional Modeling Techniques for more.
Why is Dimensional Modeling Still Relevant Today? But is dimensional modeling and all its associated concepts still relevant today? The answer is a resounding yes—perhaps even more so than before. As you've read in the preceding chapters, dimensional modeling aims to achieve a focus on business value. In today's rapidly evolving world, this crucial aspect is sometimes overlooked.
By incorporating a robust dimensional model at the core of every data project, data engineers are compelled to consider critical questions related to granularity, entities, metrics , and more. Addressing these essential aspects upfront and working towards them is invaluable for achieving business goals and driving project success.
Star Schema vs. Snowflake Schema: Kimball and Inmon In data warehousing, the star and snowflake schemas are standard data modeling techniques that are highly related to dimensional modeling.
The star schema , typically associated with Kimball's approach, has a central fact table connected to dimension tables, emphasizing staging and denormalized core data. This bottom-up approach allows for quicker access to denormalized data for analysis. Conversely, the snowflake schema further normalizes dimension tables, creating a more complex structure. This schema aligns with Inmon's approach, emphasizing a highly normalized core close to the source system, suitable for large-scale data warehousing projects.
The nuances between the Star Schema vs. Snowflake Schema and their corresponding approaches can guide data professionals in designing and implementing data warehouses, but won't dictate success or failure. Both schemas have their merits, and their choice depends on personal preference or specific project requirements. Understanding these differences allows data professionals to make informed decisions tailored to their unique projects.
Data Vault Modeling: A Flexible and Dynamic Approach Compared to dimensional modeling, Data Vault modeling is a method that addresses the challenges of modern data warehousing, mainly when dealing with big data and fast-changing data connection points. This hybrid data modeling approach combines the best aspects of 3NF (Third Normal Form) and Star Schema methodologies, resulting in a scalable, flexible, and agile solution for building data warehouses and data marts.
The primary components of a Data Vault model are Hubs, Satellites, and Links. Hubs represent business keys, Satellites store descriptive attributes, and Links define relationships between Hubs. This unique structure allows for rapid ingestion of new data sources, supports historical data tracking, and is well-suited for large-scale data integration and warehousing projects.
Moreover, Data Vault modeling has been increasingly utilized as a governed Data Lake due to its ability to adapt to changing business environments, support massive data sets, simplify data warehouse design complexities, and increase usability for business users. By modeling after the business domain, Data Vault ensures that new data sources can be added without impacting the existing design. As a result, Data Vault modeling, in conjunction with Data Warehouse Automation, is proving to be a highly effective and efficient approach to data management in contemporary data-driven business landscapes.
Anchor Modeling Anchor Modeling is an agile data modeling technique designed to handle evolving data structures like data vault modeling. It is built around storing each attribute as a separate table, allowing for more flexibility when dealing with schema changes. This approach is beneficial when the data model must frequently evolve and adapt to new requirements. Anchor Modeling is known for efficiently handling schema changes and reducing data redundancy.
Compared to data vault modeling, anchor modeling focuses on the change in information both in structure and content. It separates identities (anchors), context (attributes), relationships (ties), and finite value domains (knots). The focus is on the flexibility and temporal capabilities of the data model, capturing changes in information over time.
Bitemporal Modeling: A Comprehensive Approach to Handling Historical Data A more niche but still valid modeling technique is Bitemporal Modeling .
Bitemporal modeling is a specialized technique that handles historical data along two distinct timelines. This approach enables organizations to access data from different vantage points in time. It allows for the recreation of past reports as they appeared and how they should have appeared, given any corrections made to the data after its creation. Bitemporal modeling is beneficial in sectors like financial reporting, where maintaining accurate historical records is critical.
Focusing on the completeness and accuracy of data, bitemporal modeling allows for creating comprehensive audit trails. Using bitemporal structures as the fundamental components, this modeling technique results in databases with consistent temporality for all data. All data becomes immutable, enabling queries to provide the most accurate data possible, data as it was known at any time and information about when and why the most accurate data changed.
Bitemporal modeling can be implemented using relational and graph databases, and while it is different from dimensional modeling, it complements database normalization. The SQL:2011 standard includes language constructs for working with bitemporal data. Read more on a gentle introduction to bitemporal data challenges .
Entity-Centric Data Modeling (ECM) A relatively new modeling technique is Entity-Centric Data Modeling (ECM) introduced by Maxime Beauchemin . Entity-centric data modeling (ECM) elevates the core idea of an “entity” (i.e., user, customer, product, business unit, ad campaign, etc.) at the very top for analytics data modeling.
It's interesting as its core focuses on the strength of precisely the points discussed above that dimensional provides. As it's old, it also has some missing features that today's world is needed. That's why Max updated it and merged it with Feature Engineering , used in the ML project. You can find more in his latest article or my comments in the DataNews.filter() newsletter 📰.
Common Problems with Data Modeling Data modeling is easy to neglect; assessing the consequences can take time and effort . The image below illustrates that if you initially ignore poor data modeling and architecture decisions, you'll likely notice problems in the last mile, thinking they might be due to the tools or insights. However, the fundamental issues primarily originate in the first part of the data analytics cycle.
I love this image by Matt Arderne on Twitter. Image originally from Forbes Here are some critical data modeling problems.
Business rules
Another common issue is that entity types are often not identified or incorrectly identified . This can cause data replication, duplicated data structures, and functionality. These duplications increase the costs of development and maintenance. Data definitions should be explicit and easy to understand to prevent this problem, minimizing misinterpretation and duplication.
Data models for different systems can vary significantly , creating a need for complex interfaces between systems that share data. These interfaces can account for between 25 and 70% of the cost of current systems. To address this, required interfaces should be considered inherently during data model design, as data models would only be used independently with interfaces within different systems.
Lastly, data cannot be shared electronically with customers and suppliers because the structure and meaning of data still need to be standardized . To maximize the value of an implemented data model, it is crucial to define standards that ensure data models meet business needs and maintain consistency. This standardization will enable efficient data sharing between various stakeholders.
To mitigate these issues, tight integration into the overall data architecture and patterns can reduce friction. We'll explore these in the next part, 3.
What's Next in the Last Part? Throughout Part 2, we have explored the various data modeling approaches and techniques that serve as the backbone of data engineering. From top-down and bottom-up approaches to conceptual, logical, and physical data models, understanding these methods is crucial for effective data modeling. Techniques like dimensional, data vault, and bitemporal modeling offer unique benefits and cater to a wide range of use cases in modern data engineering. As we have seen, addressing common problems in data modeling and ensuring tight integration into the overall data architecture is essential for success.
In the next Part of this series, “Data Architecture Patterns, Tools, and The Future—Part 3 ”, we will delve into data architecture patterns, tools, and the future of data modeling. Stay tuned as we explore the fascinating world of data modeling within data engineering and its impact on the future of data-driven decision-making.