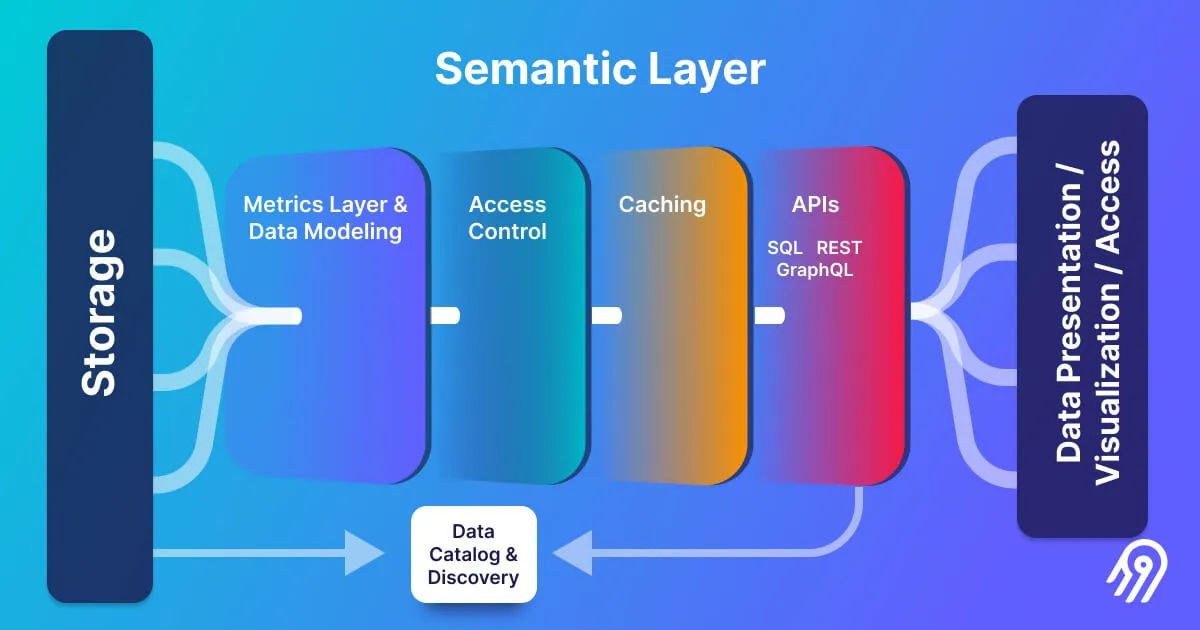
A semantic layer serves as a crucial abstraction that transforms complex data infrastructure into business-friendly analytics interfaces. By providing unified metric definitions and consistent data access across diverse tools, semantic layers have become essential for organizations seeking to democratize data while maintaining governance. The exponential growth of generative AI has fundamentally elevated the semantic layer from a convenience to a necessity, with Gartner's 2025 guidance explicitly identifying semantic technology as non-negotiable for AI success. This comprehensive guide explores the current semantic layer landscape, emerging applications in generative AI systems, and architectural innovations that enhance contextual intelligence while preventing AI hallucinations and ensuring data governance at scale.
What Tools Are Available for Building a Semantic Layer? The semantic layer tooling ecosystem has evolved significantly, with both open-source and commercial solutions addressing different organizational needs. Leading platforms include Cube , dbt's Semantic Layer , MetricFlow , and AtScale , each offering distinct approaches to metric governance and data abstraction.
dbt's Semantic Layer integrates MetricFlow's capabilities with dbt's transformation framework, enabling teams to define metrics alongside their data models and to support both batch and real-time calculation. The platform has expanded to include natural language querying capabilities that allow business users to ask questions in plain English while maintaining governance through embedded metadata validation.
Cube continues to lead in the headless BI space, offering API-first semantic layer capabilities, semantic caching, pre-aggregations, and multi-tenant security. Recent enhancements include native vector database support and AI-powered query optimization that automatically suggests relevant dimensions when users request specific metrics.
AtScale focuses on enterprise-grade implementations and has introduced an open standard—Semantic Modeling Language (SML) —for portable metric definitions. Their September 2024 release of SML as Apache-licensed open-source provides a universal YAML-based specification that supports both tabular and multidimensional constructs across any application, addressing the systemic issues of proprietary semantic layers including inconsistent metrics and costly vendor lock-in.
When do you need such a tool? How Do Semantic Layers Enable Trustworthy Generative AI and RAG Systems? Generative AI systems often hallucinate when they lack business context, but semantic layers ground these systems in validated definitions and provide the structured metadata that AI systems require for reliable operation. Large language models exhibit alarming hallucination rates as high as 80% in benchmark tests when ungrounded in semantic context but achieve near-perfect accuracy when integrated with robust semantic layers. Those misfires are already in court, with more than 40 active lawsuits over how AI models were built and trained, so vendors now carry liability coverage for these claims.
Technical Implementation Patterns Modern implementations like Snowflake's semantic views store semantic model information natively in the database, providing AI-powered conversational interfaces that access consistent metrics alongside traditional BI tools. These systems incorporate verified queries and custom instructions that specifically guide Cortex Analyst responses, essentially providing AI systems with business-contextualized guardrails.
Enterprise Adoption Frameworks Organizations progress from curated datasets to real-time query-resolution systems and finally to agentic ecosystems where semantic layers serve as the "truth coordinates" for AI agents. The practical implementation trend shows strong movement toward semantic layers that embed directly within modern data stacks rather than operating as bolt-on solutions.
Performance and Accuracy Benefits Semantic layers eliminate ambiguity around terms like "active customer" or "recurring revenue," boosting user trust and regulatory compliance. AtScale reports accuracy improvements of over 300% versus direct database queries when semantic context guides AI responses. The semantic layer functions as the crucial intermediary that translates human intent into structured queries while embedding business context that AI systems require for accurate interpretation.
What Are AI-Powered Semantic Enhancement and Automation Capabilities? Artificial intelligence has dramatically expanded the functional boundaries of semantic layers, transforming them from static definition repositories to dynamic, intelligent systems that autonomously maintain and adapt semantic definitions based on usage patterns and evolving business requirements.
Natural Language Processing Integration Natural Language Processing capabilities are fundamentally transforming semantic layer accessibility by enabling non-technical users to query data using conversational language rather than technical syntax. These systems interpret phrases like "Show Q3 sales growth in European regions" and automatically map them to underlying metrics through AI-powered parsing of business glossaries and ontologies. Advanced NLP implementations now incorporate multimodal understanding, processing voice queries and unstructured text alongside traditional inputs, resulting in a 40% reduction in analysis time for non-technical users while simultaneously reducing dependency on data specialists for routine investigation.
Modern semantic layers incorporating transformer-based models analyze query patterns to proactively suggest related dimensions—when users request "quarterly performance," systems automatically surface time comparisons, regional breakdowns, and product category filters. This anticipatory intelligence reduces analytical friction while maintaining governance through embedded metadata validation, effectively allowing business users to "talk" to their data using natural business terminology rather than technical schema language.
Machine Learning for Automated Metadata Management Machine learning algorithms now automate labor-intensive semantic layer maintenance tasks that previously required extensive manual curation. Systems employ clustering algorithms to identify synonym relationships across disparate data sources—automatically linking "custid," "client identifier," and "customer_number" entities based on distribution patterns and usage context. Reinforcement learning models continuously optimize query performance by analyzing usage patterns, where frequently accessed metrics are dynamically cached while infrequently used attributes deprioritize resource allocation.
Generative AI is revolutionizing semantic modeling workflows by creating draft semantic models from technical documentation. Large language models trained on industry-specific corpora can automatically map clinical trial attributes to healthcare standards or financial metrics to regulatory frameworks, accelerating ontology development by 60-70% compared to manual approaches. These systems incorporate human feedback loops where domain experts validate AI suggestions, creating continuous improvement cycles that enhance semantic accuracy while reducing implementation timelines.
Predictive Analytics and Pattern Detection Pattern detection and forecasting represent another frontier for AI enhancement within semantic layers. Modern implementations incorporate machine learning algorithms that automatically identify anomalies, surface significant trends, and generate predictive insights based on governed metric definitions. These systems provide multi-source pattern recognition that correlates events across disparate systems, enabling comprehensive insight generation that transcends individual data silos.
The forecast modeling capabilities are particularly notable, as they leverage semantic layer definitions to ensure consistent application of business rules across predictive scenarios. AI-driven analysis flags unusual patterns in time-series data without manual threshold configuration, while predictive metric ecosystems enable definitions like "predicted Q4 revenue" through integrated ML pipelines that automatically trigger retraining workflows when source data drifts beyond established thresholds.
How Do Real-Time Semantic Processing and Streaming Integration Work? Real-time analytics requirements have driven semantic layer innovation beyond traditional batch-oriented processing, particularly in streaming data environments where immediate interpretation of high-velocity data directly impacts business outcomes. Modern semantic layers now incorporate capabilities specifically designed for real-time contexts, including support for streaming data platforms, dynamic schema adaptation, and low-latency query processing.
Event-Driven Semantic Synchronization Modern semantic layers adopt change data capture (CDC) methodologies to maintain synchronization with evolving source systems, ensuring metric definitions remain consistent when underlying schemas evolve. Platforms embedded within semantic layers detect schema modifications at source databases, automatically propagating ALTER TABLE operations to semantic models while preserving existing business mappings. This event-driven architecture proves critical for financial reporting compliance where calculation logic must persist across structural changes.
Real-time semantic layers now incorporate temporal versioning that maintains immutable audit trails of semantic definition changes. When business logic for "customer lifetime value" evolves, previous definitions remain accessible for historical reporting while new calculations govern current dashboards—all managed through temporal graph databases. This approach maintains regulatory compliance while enabling agile metric evolution, addressing the core challenge of maintaining governance in dynamic business environments.
Streaming Semantic Materialization Innovative semantic layers now materialize computations within data streams rather than post-processing batch results. Systems enable semantic definitions to execute directly on streaming platforms, where retail applications demonstrate real-time computation of "inventory turnover rates" within streaming message queues. Semantic logic calculates ratios between sales events and stock update streams, eliminating ETL latency for time-sensitive metrics while reducing computational overhead through incremental updates.
Semantic streaming extends to complex event processing where financial institutions implement pattern recognition engines within semantic layers to detect conditions like "three consecutive transaction declines followed by high-value international transfer." These semantic patterns trigger real-time alerts while maintaining contextual consistency with batch-derived customer profiles, with the semantic layer acting as the unification point where streaming logic seamlessly integrates with historical business definitions.
Hybrid Query Processing Architecture Emerging hybrid execution frameworks bridge real-time and historical analysis within semantic layers by integrating streaming engines that maintain incrementally updated semantic representations of real-time data streams. This enables semantic layers to seamlessly combine live transactional data with historical warehouses—executing joins between streaming inventory data and historical sales data without manual pipeline development.
Advanced implementations incorporate probabilistic query planning that generates approximate results with confidence intervals when semantic layers detect partially available real-time data. This capability supports time-sensitive decision-making while maintaining audit trails for subsequent reconciliation, with systems maintaining semantic consistency by applying identical business rules to both streaming and batch contexts through centralized logic repositories.
What Are Graph-Powered Semantic Architectures and How Do They Enhance Contextual Intelligence? Combining semantic layers with graph technology yields knowledge-enabled data fabrics that capture relationships among business entities, establishing contextual relationships between disparate data elements through RDF-based knowledge graphs as foundational integration frameworks.
Architectural Integration Models Metadata graphs track lineage while business knowledge graphs encode ontologies. These graphs establish contextual relationships between disparate data elements: linking CRM "opportunity" objects to ERP "purchase order" entities through explicit business relationships. This graph-based contextualization enables sophisticated queries like "show marketing campaign ROI against support ticket reduction" without predefined joins, allowing the system to traverse relationships while honoring semantic definitions.
Knowledge graphs now incorporate probabilistic reasoning for incomplete data, where healthcare semantic layers use probabilistic graph networks to infer connections between clinical trials when explicit linkages are absent. By analyzing co-occurrence patterns and semantic similarities, these systems hypothesize relationships with confidence scores—accelerating research discovery while maintaining audit trails of inferred connections. All inferences remain constrained by ontological business rules, preventing erroneous relationships.
Contextual-Intelligence Applications Advanced Query Capabilities Analysts can ask: "Which customers purchased products from suppliers experiencing quality issues?"—the system traverses relationships while honoring semantic definitions. Graph-RAG (Retrieval Augmented Generation) architecture leverages semantic relationships to retrieve contextually precise information, where pharmaceutical implementations traverse knowledge graphs to retrieve connected pharmacological pathways, adverse event reports, and trial outcomes—generating responses grounded in explicit relationships rather than statistical word associations.
What Challenges Come With Implementing Semantic Layers? While semantic layers provide significant benefits, organizations face several implementation challenges that require careful consideration and strategic planning:
How Do Semantic Layers Compare to Data Marts and Presentation Layers? Semantic LayerData MartPresentation LayerPurpose Abstraction & metric governanceDomain-specific storageVisualization & UXContent Business logic & definitionsTransformed analytical dataDashboards, reportsAudience Analysts & BI developersDepartmental analystsExecutives & end-usersDeployment Logical abstraction layerPhysical data storageUser interface componentsMaintenance Metric definitions & relationshipsData refreshes & storageVisual designs & interactions
The three layers are complementary rather than competitive: the semantic layer supplies consistent business logic that data marts feed and presentation tools consume. This relationship enables organizations to maintain consistent metric definitions while supporting diverse analytical needs across different user personas and use cases.
How Do Semantic Layers Differ From OLAP, Data Virtualization, and Data Mesh? Understanding the distinctions between semantic layers and related technologies helps organizations make informed architectural decisions:
OLAP Cubes Provide pre-aggregated multi-dimensional structures optimized for specific query patterns but are less flexible than semantic layers. While OLAP cubes offer excellent performance for predefined analytical paths, semantic layers provide dynamic metric calculation and broader adaptability to evolving business requirements.
Data Virtualization & Federation Offer unified query access across disparate data sources; a semantic layer adds business context and governance on top of this technical integration. Data virtualization handles the technical complexity of federated queries, while semantic layers ensure consistent business interpretation of the results.
Data Mesh & Data Contracts Data mesh decentralizes data ownership across domains; a semantic layer can expose standardized interfaces for domain data products while preserving autonomy. Semantic layers function as the unifying framework that maintains standardized definitions across distributed domains, serving as the contract enforcement mechanism that ensures interoperability between independently developed data products.
Data Catalogs Catalogs aid discovery and documentation; semantic layers ensure consistent meaning and calculation for discovered assets. While data catalogs help users find relevant data, semantic layers ensure that data means the same thing regardless of how it's accessed or by whom.
Will Semantic Layers Experience Broader Adoption? The semantic layer market shows strong adoption momentum driven by several converging factors that make implementation increasingly necessary rather than optional:
Adoption Drivers : Multi-tool environments where organizations use multiple BI platforms, the rise of generative AI requiring semantic context for accurate responses, cloud warehouse performance enabling real-time semantic processing, and regulatory requirements demanding consistent metric definitions across business units.
Market Barriers : Integration effort requiring dedicated resources and expertise, the need for dedicated governance frameworks, and organizational change management challenges when transitioning from ad-hoc to centralized metric definitions.
Adoption Patterns : Large, regulated enterprises are adopting fastest due to compliance requirements and complex multi-tool environments. Mid-market organizations follow when analytical complexity reaches thresholds where inconsistent metrics create business risks. Smaller teams may rely on simpler approaches until data volume and tool diversity demands a semantic layer.
Gartner's 2025 guidance explicitly states that semantic modeling has transitioned from optional to foundational, with their research positioning semantic technology as essential infrastructure for AI success. This authoritative validation confirms market observations that organizations without semantic layers risk feeding AI systems incomplete context, undermining analytical accuracy and business trust.
How Does Airbyte Support Semantic Layer Implementation? Airbyte delivers the foundational data integration capabilities that enable successful semantic layer implementations, providing reliable, governed data pipelines that semantic layers depend on for consistent and accurate business intelligence.
Data Integration for Semantic Consistency Airbyte's 600+ connectors ensure comprehensive data source coverage, supporting both structured and unstructured data synchronization that semantic layers require for complete business context. The platform's change data capture (CDC) capabilities maintain real-time synchronization between source systems and semantic layers, while automated schema evolution handling preserves semantic definitions even when underlying data structures change.
Recent innovations like the July 2025 "Files + Records" update address a critical semantic layer requirement by synchronizing unstructured files with structured records in single pipelines. This contextual data synchronization preserves the relationships that semantic layers need to provide complete business understanding—for example, linking customer support tickets with call recordings or connecting financial transactions with supporting documentation.
Enabling Analytics-Ready Data Pipelines Tight integration with dbt enables semantic layer implementations that leverage Airbyte's reliable data movement alongside dbt's transformation and semantic modeling capabilities. PyAirbyte provides programmatic validation capabilities that ensure data quality before semantic layer consumption, while vector database connectors support AI-enhanced semantic layers that incorporate embedding-based context retrieval.
Direct loading capabilities optimize semantic layer performance by reducing data transfer latency and computational overhead. By bypassing intermediate staging, data reaches semantic layers and downstream analytics systems 33% faster, enabling real-time semantic processing that supports immediate business decision-making.
Supporting Governance and Compliance Airbyte's enterprise-grade security and governance capabilities provide the foundation that semantic layers require for regulated industries and sensitive data handling. End-to-end encryption, role-based access control (RBAC), and comprehensive audit logging ensure that data feeding semantic layers maintains security and compliance standards throughout the integration pipeline.
Multi-region data plane capabilities support data sovereignty requirements while maintaining centralized semantic layer management. Australian healthcare data remains in Sydney AWS while EU customer data stays in Frankfurt Azure, all governed by consistent semantic definitions managed through Airbyte's unified control plane. This architecture enables global semantic consistency while meeting local regulatory requirements.
FAQs How to build a semantic layer? How do different business applications use the semantic layer? How do semantic layers help LLMs better interpret data? Semantic layers provide structured business context that LLMs can query, preventing hallucinations and enabling accurate, explainable insights. They supply the governed metadata that AI systems require for reliable operation, translating natural language requests into validated business logic while maintaining audit trails for regulatory compliance.
What is the difference between a semantic layer and a metrics layer? While often used interchangeably, semantic layers provide broader business context through ontological relationships, while metrics layers focus specifically on calculation consistency and data refinement. Semantic layers encompass metrics layers but extend beyond calculation to include entity relationships, business definitions, and contextual intelligence.
For further reading, see Airbyte's glossary entry: What is a Semantic Layer? .
What Tools Are Out There for Building a Semantic Layer? As we’ve now learned a lot about the semantic layer, let's see actual tools, focusing on open-source.
The most commonly named tools are Cube.js (recently renamed Cube), MetricFlow , MetriQL , dbt Metrics , or Malloy . Where MetriQL was the first open-source but Transform.co working on a closed-source version that eventually got open-sourced into MetricFlow. Also, dbt announced their metrics system back at Coalesce the Metric System , and turning it now into dbt Semantic Layer (more to come in October at dbt Coalesce Conference). According to GitHub stars, Cube is the fastest growing tool in this area, and already has many integrations including data sources and data visualizations – for example, it integrates with dbt Metrics.
MetricFlow and Cube’s semantic layer overview is fascinating to compare, where Cube talks about headless BI and MetricFlow about the metrics layer. As discussed above, you understand why both try to address not only the metrics part but also data modeling and abstract away all data sources by adding access control, caching, and APIs.
Overview of a Semantic Layer by Cube (top) and MetricFlow (bottom) When do you need such a tool? There are two initial use cases: First, if you won’t build a significant data architecture, you could start with your sources and access your data sources or cloud warehouse. The second one is when your company size and data-savvy people are growing. More people need transformations, defining metrics, or adding many data and SaaS tools ; you need alignment around definitions.
Some trends : Supergrain initially also had a metrics layer but pivoted to personalized marketing. If we look solely at the GitHub stars, it is a bit unfair for MetricFlow as they worked to log on that problem but only open-sourced it, but still, it gives a good impression about cube.js. They also just announced the Unbundling of Looker in combination with Superset. Furthermore, there is a dedicated Semantic Layer Summit .
Open-source semantic layer solutions compared on GitHub Star History A deeper comparison of the tools you find on How is this different from . There is an extensive list of closed-source solutions such as uMetric by Uber, Minerva by Airbnb, Veezoo , and more.
🐦 Unpopular Opinion: The Metrics Stores are just BI Tools that evolve into full-fledged BI tools over time [Tweet ] I think I actually agree with this. But, I don’t think BI Tools will exist as they do today. Instead, there will be data applications that will rely on semantics expressed in Metrics Stores. The Metrics Store will need governance + discovery that includes graphs(“BI”) + metadata” . 💬 An interesting announcement about the Customer Data Platform (CDP) , a relatively new term, and companies already pivoting away from it. Hightouch talks about “legacy CPD”. Fascinating to me, because the new data architecture looks like a semantic layer on top of the data warehouse, or is it just me? Semantic Layer Challenges Besides all the positive things mentioned, some challenges come with a semantic layer. First of all, it is another layer that needs integration with many other tools. Another significant downside is having to learn another solution that needs to be operationalized as a critical component of your data stack. The cost of maintaining and creating such a layer is high.
There is also a hidden complexity in generating these queries on the fly. Every query needs to be generated for different SQL dialects–e.g., Postgres SQL and Oracle SQL are not 1:1 the same. That can be both problematic in terms of latency but also in terms of producing a faulty SQL query . The counter-argument is that it’s still easier to maintain copies of data sets and re-do the metrics repetitively inside a BI dashboard.
When you use extensive exposed APIs, you might run into performance issues, as pulling lots of data over REST or GraphQL is less than ideal. You can always switch to SQL directly, but mostly with losing some comfort.
As always, it depends on the criticality of centrally defined metrics that everyone agrees on, or you can live in minor drift away in different tools.
🗣 What others are saying: JP Monteiro is saying in his deep dive : “I find it unlikely that the best practice will still be to have one place to define metrics and one place to define dimensions, once the querying layer part is solved. In fact, lineage between concepts is part of “semantics”: it helps us understand how one concept is related to another —which makes you really question if ‘column-level lineage’ is the right level of abstraction we should talk about: columns are too raw ".
Semantic layer vs data mart vs presentation layer Purpose Semantic Layer: It serves as a connector between sources of raw data and the presentation layer, providing a collective view of the data and abstracting away the complexities of underlying data structures.Data Mart: It is a subset of a data warehouse designed to serve a specific department or line of business, containing a tailored set of data optimized for analysis and reporting.Presentation Layer: In this layer the data is visualized and presented to the end-users, often in the form of dashboards, reports, or applications, making it understandable and actionable.Content Semantic Layer: This layer includes different business logic, data definitions, and relationships between various data elements, enabling users to query and analyze data with the help of familiar business terms rather than database terminology.Data Mart: It contains structured data relevant to a particular business function or area, such as sales, marketing, or finance, organized for analytical purposes.Presentation Layer: It has a visual representation of data, which includes charts, graphs, tables, and interactive elements, designed to facilitate decision-making and insight generation.Audience Semantic Layer: It is primarily designed for data analysts, business intelligence professionals, and other technical users who need to access and analyze data across different sources in a consistent manner.Data Mart: It serves business users and analysts within a specific department or business unit, providing them with relevant and tailored data for their analytical needs. Presentation Layer: It caters to a broader audience, including executives, managers, and operational staff, who rely on intuitive and informative visualizations to understand trends, identify patterns, and make informed decisions.What’s the Difference to OLAP, Data Cataloging, Virtualizations, or Mesh As the semantic layer is something central and intertwined with lots of related data engineering concepts , we discuss here how they relate to each other.
OLAP Cubes As part of the semantic layer, the cache layer can be seen as a replacement for modern OLAP cubes such as Apache Druid , Apache Pinot , and ClickHouse . Similar attributes with defining the queries ad-hoc and delivering sub-second query times. OLAP cubes are the fastest way to query your data if you do not have updates in your data.
Compared to an OLAP solution, the benefit of the semantic layer is avoiding reingesting your data into another tool and format; it happens under the hood, for good or worse. A caching layer is another complex piece, as it's always outdated as you add more data; it needs to constantly update its cache as you do not want to query old invalidated data.
That's also where it gets interesting how semantic layer tools solve it. For example, Cube tried to implement with Redis but reverted and built their own caching layer from scratch. On the upside, OLAP cubes have built-in computing where you can run heavy queries .
Data Virtualization and Federation Data Virtualization comes up in many discussions related to the semantic layer. Still, even more to the semantic layer is data virtualization, with tools such as Dremio that try to have all data in-memory with technologies such as Apache Arrow . Data federation, very similar to virtualization, mostly referred to technologies like Presto or Trino .
These are versions of a semantic layer, including a cache layer with access management, data governance, and many more. It has a powerful option to join data in its semantic layer . In a way, they are the perfect semantic layer, although Dremio, and also Presto have branded themself as an open data lakehouse platform lately. Which brings us to another question.
Is a lakehouse nothing else than a semantic layer?
In a way, they have similar attributes, but a lakehouse includes an open storage layer (Delta Lake, Iceberg, Hudi ). In contrast, the semantic layer is more ad-hoc, query-time driven. Still, the lakehouse from Databricks tries to store only once and avoid data movement as much as possible by querying it with their compute engine Photon .
The problem is, the platform itself is not open-source, only storage, and the metrics are not defined in a declarative way. They are mostly entangled in notebooks or UI-based tools.
📝 Dremio has patented database-like indexes on source systems with Data Reflections . They are producing more cost-effective query plans than performing query push-downs to the data sources.
Data Mesh and Data Contracts Two recent popular terms are Data Mesh and Data Contract . Both are pulling in the same direction of giving more power to the domain experts who know the data best, away from engineers who should be more focused on a stable system.
In my opinion, giving more control also needs an easier way for these domain experts to define their metrics in a standardized way, being declarative directly on the Data Assets , but with a standardized tool—which is the semantic layer for me. But in contrast to data mesh, which is decentralized, the semantic layer fancies a very centralized approach for metrics.
Data Catalogs A data catalog is another way of centralizing metrics and Data Products . It’s similar to a semantic layer but focuses more on the physical data assets than the metrics query. Plus, it has another focus: providing a Google search to your data assets such as dashboards, warehouse tables, or models. Modern tools such as Amundsen or DataHub allow you to rate and comment on the data assets, adding metadata such as an owner so that people easily find the best data collaboratively set for their job.
The Semantic Warehouse A Semantic Warehouse is a term I heard from Chad Sanderson for the first time a month ago. He does a great job putting the words semantic layer, semantic mapping , metrics layer, and data catalog on a data map, as seen in the image below.
An overview of Semantic Warehouse by Chad Sanderson What’s interesting here is that the semantic layer is directly on top of the apps, services, and DB between semantic mappings and the metrics layer. It acts as a Data Contract between the real world and the data team. In my opinion, this is what a semantic layer is described in great detail above.
Analytics API In the above semantic warehouse illustration, the semantic mapping seems to be the data orchestrator , and the metrics layer is the subset of the semantic layer that holds the metrics themselves. This is interesting because I implemented such a thing (parts of it), and I wrote about it in a similar way in Building an Analytics API with GraphQL . I called it Analytics API with its core components of an API and query engine, data catalog, data orchestrator, a SQL connector, and of course, the metrics layer. It has the same function and the same component but is visualized as a single analytics API component. Queries through the access layer connecting heterogeneous data stores.
Suggested read: Data Catalog vs. Data Discovery
Will the Semantic Layer Get More Adoption? The semantic layer is an abstract construct that is hard to grasp. It has many touching points with existing concepts and similarities with other upcoming ones.
If it were a new construct, I'd say it's just another buzzword. But as it started in 1991, as seen in the history of the semantic layer, and evolved into the modern data stack and adapted to today's needs.
It's still hard to implement all features we've discussed here; that's the theoretical view. But I believe if you start with getting a more diverse architecture with lots of spread-out tools, the semantic layer has its stands for staying. Start with your basic requirements. Maybe you need a central access layer for people to access data quickly. Or you do not want to add another complex layer with an OLAP cube on top and search for an efficient cache layer. Or most importantly, if you're going to define your metric in a central place with a thin layer, start with the concept of the semantic layer and its definition of metrics.
Learn along the way. Check out the above tools mentioned and see if they work out. These days, the tech makes it very easy to start a POC, e.g., define some of your BI metrics inside a semantic layer and sync it into your BI tool. Try to get a feeling for it.
Besides the must needs such as data integration, transformation at ingest, visualizing, and orchestrating, I see the semantic layer as the next step for defining metrics in a standardized way.
—
If you want to read more, I pulled together an extensive list of other articles on that topic in our data glossary on What is a Semantic Layer .
If you are curious about how we Build the Data Stack and integrate a semantic layer at Airbyte and stay up to date with our Newsletter , we plan to share a hands-on tutorial about it. Or, if you want to chat with 9000+ data people and us, join our Community Slack .
FAQs How to build a semantic layer? Before constructing the semantic layer, analyze the data sources and business requirements. Next, determine the definitions, relationships, and important data entities. Then, create a logical data model that satisfies business requirements while abstracting technical complexities. Utilize a business intelligence platform or a data modeling tool to put the model into practice. Finally, ensure that the semantic layer provides precise, consistent, and useful insights by iteratively validating and improving it based on feedback from stakeholders.
How do different business applications use the semantic layer? Semantic layers serve multiple purposes across various domains within the realm of data management and analytics. In business intelligence (BI) tools, they provide users with a unified perspective of data, streamlining reporting and querying processes. Data virtualization tools leverage semantic layers to seamlessly integrate disparate data sources, thereby enhancing data agility and accessibility. Data analysis tools utilize semantic layers to enhance analytical capabilities and comprehend intricate data relationships. Moreover, within data governance systems, semantic layers play a pivotal role in enforcing standardized data definitions, access restrictions, and compliance guidelines throughout the organization.
How do semantic layers help LLMs better interpret data? Semantic layers significantly enhance the interpretative capabilities of Large Language Models (LLMs) by providing a structured, contextual framework for data analysis. By abstracting complex data structures and technical specifics, semantic layers enable LLMs to access and analyze data uniformly, thus improving their ability to understand intricate relationships and contextual nuances. This unified approach allows LLMs to deliver more precise and insightful analyses, making them invaluable tools in decision-making processes across various domains. As LLMs apply these layers, they better identify trends, contextualize information, and generate accurate insights, supporting users in navigating and making informed decisions in complex environments. This refined processing aids in bridging the gap between vast data sets and practical, actionable intelligence.