New: Airbyte Agents. Context-aware AI, built on your data.
Blog
/
Data
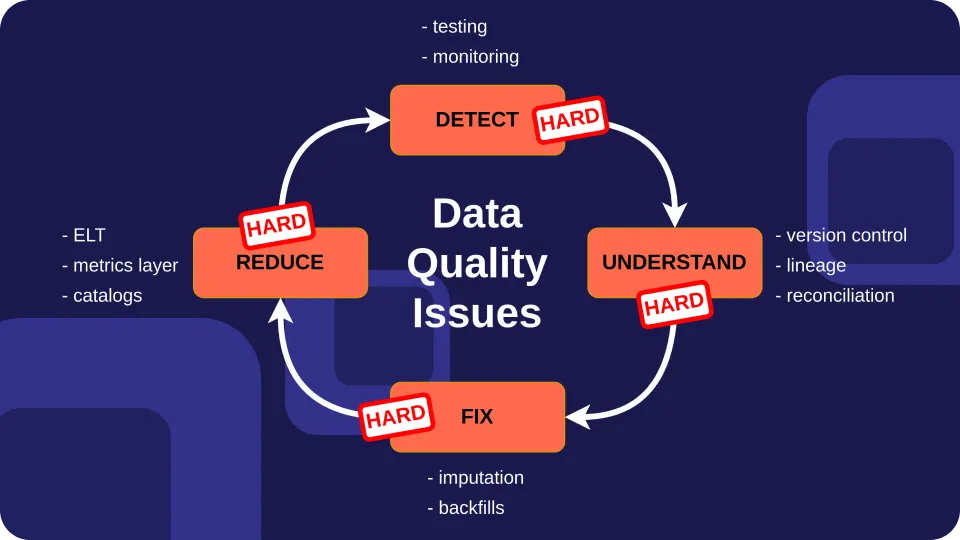
Data quality issues arise when data fails to meet expectations. Best practices inspired by code quality make data quality an easier problem to solve.
Summarize with AI:
About the Author
Ari Bajo Rouvinen
Ari Bajo is a Data Engineer and Technical Writer at Airbyte. Previously, Ari has lead data teams at French strartups.
Be among the first to explore our new platform and get access to our latest features.
Join our newsletter to get all the insights on the data stack