
All ETL tool comparison
Airbyte vs Prefect
Uncover the key differences between Airbyte and Prefect in this showdown. Find out which tool best suits your data workflow and integration needs.

VS

VS
Convinced? Move to Airbyte and build seamless data pipelines hassle-free
Try a 14-day free trial
Key Distinction Between Airbyte vs Prefect
Let’s consider some of the factors to understand Airbyte vs Prefect differences in detail:
Build and Orchestrate Data Pipelines
With Airbyte, you can build ETL pipelines using a user-intuitive interface, API, and Terraform Provider. In addition, you can also build ELT pipelines by utilizing an open-source, developer-friendly Python library called PyAirbyte. It helps you extract data using Airbyte connectors and load it into various SQL caches like DuckDB, BigQuery, and Snowflake.
You can then convert this SQL cache into a Pandas DataFrame within your Python workflows to read and transform the data. After preparing your data, you can select from the supported destination connectors or use the specific Python client APIs for your preferred platform.
To further automate your workflows, you can integrate Airbyte with data orchestration tools like Apache Airflow, Kestra, and Dagster.
On the other hand, Prefect allows you to orchestrate these pipelines by defining Python functions in your local or cloud environment, followed by a @task decorator. If you are using the open-source version, you must install it using the pip install Prefect command before creating your tasks for ETL processes. Then, you must generate a flow that helps you organize your tasks in the correct order using @flow decorator. You can use the flow function to execute your ETL pipeline.
AI Workflows
With Airbyte, you can simplify your AI workflows by loading unstructured data into its supported vector databases like Pinecone, Milvus, or Weaviate. This integration enables you to leverage the advanced capabilities of vector stores for similarity search and retrieval of high-dimensional data required for AI-driven applications.
You can also transfer your data to Airbyte’s AI-enabled data warehouses like Snowflake Cortex or BigQuery Vertex AI. These platforms provide powerful analytical features, enabling you to perform queries based on up-to-date data and gain actionable insights to help you enhance your AI innovations.
Conversely, Prefect's latest version, Prefect 3.0, introduced a Python framework known as ControlFlow to help you develop AI workflows. After importing the ControlFlow in Python, you can create a task, assign it to an AI agent, and return the result using the run() function.
Custom Data Transformations
For ELT workflows, you can integrate Airbyte with dbt and perform complex transformations after the data sync. Once transformed, you can efficiently use the processed data for analytics and reporting tasks.
Airbyte also supports RAG-based transformations, including OpenAI-enabled embeddings and LangChain-powered chunking, to store your unstructured data into vector databases. These data processing techniques help you make the data easily accessible to LLM applications.
In contrast, with Prefect, you can perform transformations by creating tasks using the @task decorator in your Python environment. Each task can represent a single operation, such as filtering, aggregating, or enriching data.
Pricing
Besides an open-source version, Airbyte offers three scalable pricing plans—Airbyte Cloud, Team, and Enterprise. The Cloud plan includes volume-based pricing suitable for organizations who know their data volumes upfront. The Team plan is designed for growing businesses, providing additional features like role-based access control, column hashing, and secure access with SSO. The Enterprise plan is tailored for large organizations with complex integration needs. Both Team and Enterprise versions have a capacity-based pricing model whose cost depends on the number of pipelines syncing data at a given time.
In comparison, Perfect provides the following plans:
- Pro: For startups and small-sized companies, the Pro version is suitable. It allows up to 20 users to help you create hundreds of automation in a single Prefect account.
- Enterprise: The Enterprise edition is useful for meeting strict compliance and security requirements. It offers role-based access control, directory sync (SCIM), and 24x7 support.
Benefits of Airbyte
- Airbyte provides multiple options, such as UI, API, Terraform Provider, and PyAirbyte, to help you build and manage the data pipelines according to your use case.
- By integrating with Airflow, Dagster, Prefect, and Kestra, Airbyte helps you orchestrate your data pipelines quickly.
- You can maintain a history of changes made to the data with the record change history feature in Airbyte.
- Airbyte offers automatic chunking and indexing features, enabling you to transform raw data and store it in a vector database.
- You can generate vector embeddings for LLM-powered applications using integrated Airbyte support with the leading LLM providers, such as OpenAI, Cohere, and Anthropic.
- The Airbyte forum enables you to ask questions and receive help regarding data integration practices, troubleshooting, and development strategies.
Limitations with Prefect
- Prefect is language-specific; it supports only Python to help you observe and orchestrate the pipelines.
- As Prefect is a code-based tool, you must write a Python script to define, manage, and schedule your workflows, which can be challenging for non-developers.
- Prefect supports limited integrations, which makes it difficult to connect with varied external services.
Airbyte 1.0 Workflow Automation Capabilities
With the release of Airbyte 1.0, Airbyte now offers more workflow automation capabilities, allowing you to leverage AI-powered features.
- AI-Assistant Connector Builder: The AI-Assistant connector builder provides smart suggestions for automatically prefilling the necessary fields when configuring a source or destination connector. With this new capability, you can automate most of the setup and configuration, accelerating the connector development process.
- Vector Databases Support: Vector databases such as Pinecone, Weaviate, Milvus, and Qdrant simplify your AI workflows. You can load raw data directly into these destinations for efficient similarity search and quick retrieval, making the data easily accessible for your GenAI applications.
- Automatic Detection of Dropped Records: While moving your data from source to destination, there can be some instances when your data records get dropped in transit. This can happen due to improper data flushing, parsing failures, or extremely large datasets. Airbyte provides you with a feature that automatically maintains the record count and notifies you if it detects any accidental data loss.
Tutorial for Data Movement from Sentry to Pinecone Using Airbyte
Let’s understand these capabilities clearly with a step-by-step tutorial on developing an AI model to predict future errors and make recommendations for optimizing application performance. The data source for this project is Sentry, an application performance monitoring and error handling tool.
Directly accessing unstructured data from the Sentry API can lead to several challenges, such as a lack of standardized format and data model compatibility. This can, in turn, affect the performance and scalability of the AI model.
Airbyte, on the other hand, facilitates integration with LLM providers like LangChain and LlamaIndex. It enables automatic chunking and indexing to transform raw, unstructured Sentry data and store it in the preferred vector databases.
The platform also allows the generation of embedding by supporting pre-built LLM providers compatible with Cohere, OpenAI, and Anthropic. All these features make data even more accessible to AI models, streamlining feature extraction and predictive analysis.
Based on the requirements, Airbyte’s AI assistant can help develop a custom source connector for Sentry in minutes. The steps involved are mentioned below:
Prerequisites:
- An active account in Sentry and obtain an API key.
Steps to develop a Sentry custom connector:
- Create or sign in to the Airbyte Cloud account. Alternatively, Airbyte can be deployed on the local system.
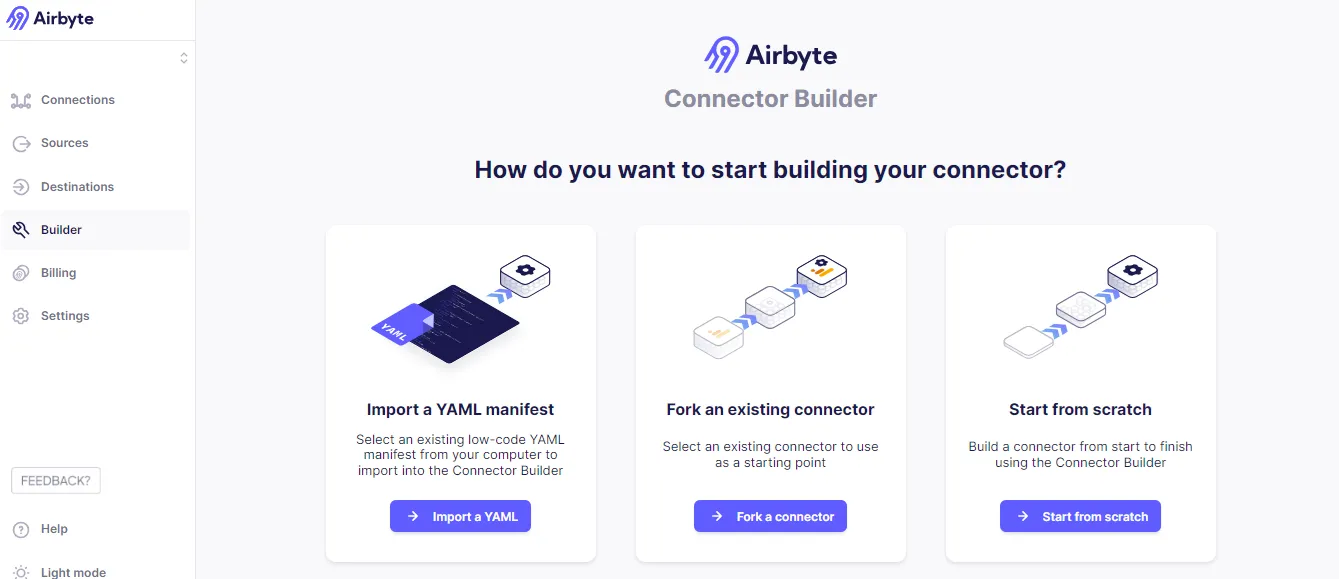
- Among the tabs on the left navigation pane of the Airbyte dashboard, click on the Builder tab.
- Click on the Start from scratch button, which redirects to a page where source connector configuration can begin using the AI assistant.
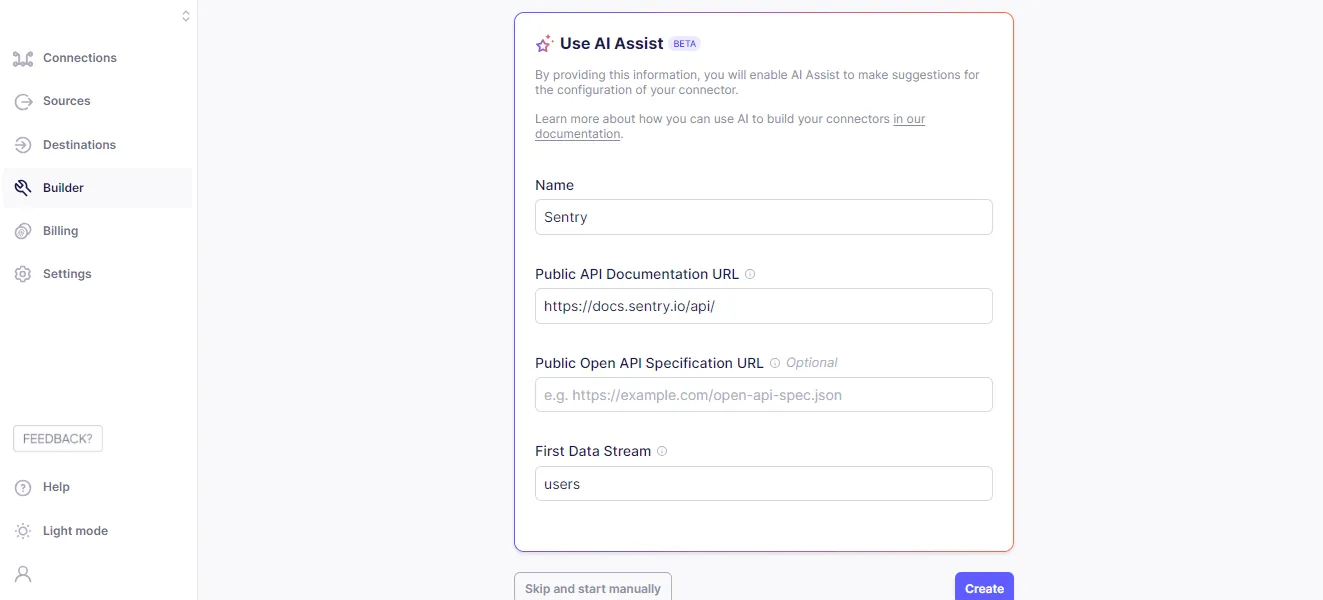
- Search for Sentry’s API reference documentation on Google, copy the URL, and paste it into the Public API Documentation URL field.
- The next step involves filling out all the fields, such as Name and First Data Stream (provide the first object’s name from the API that you want to load into your destination).
- Click the Create button and let the AI assistant take over to complete the configuration process.
- In the Sentry source connector configuration page, add the required number of streams by clicking on the + symbol next to the STREAM option.
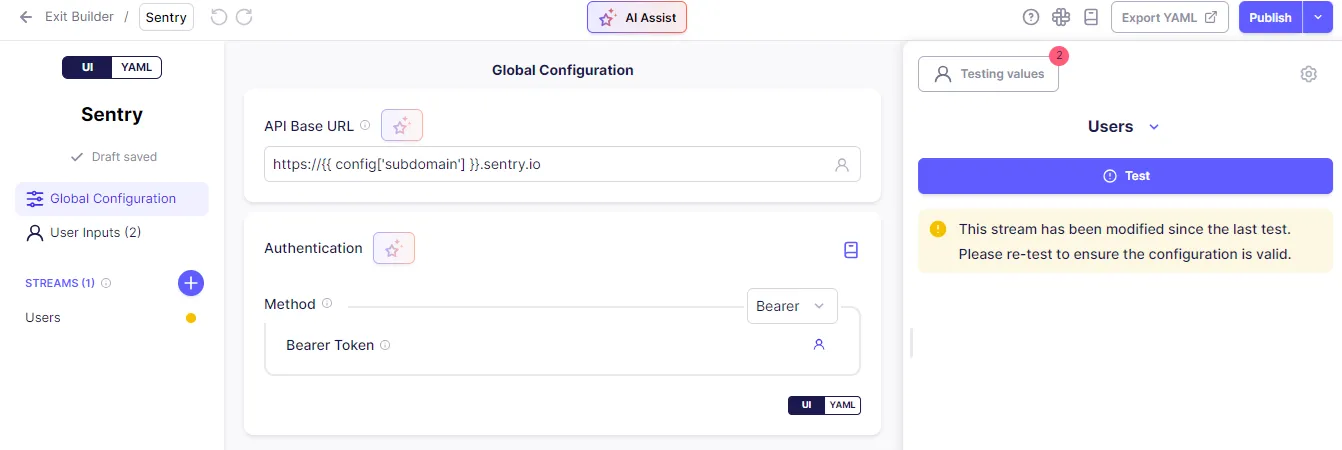
- After setting up the Sentry connector, click on the Publish button.
- In the Publish connector page, either select Publish to workspace or Contribute to Airbyte and click the Publish button.
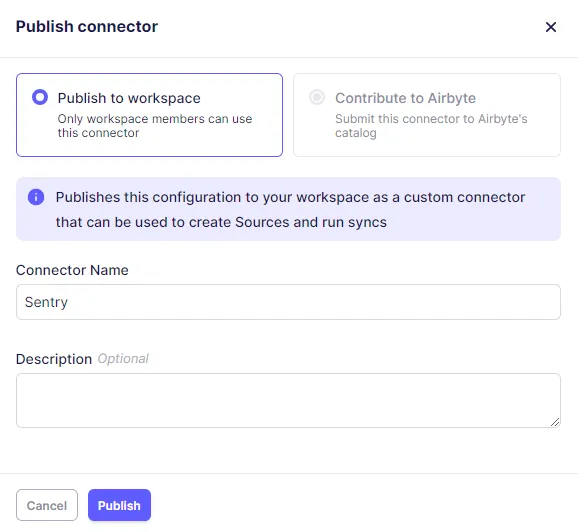
This successfully publishes the Sentry connector. The next step involves creating a data pipeline between Sentry and a supported vector database, such as Pinecone.
Prerequisites:
- Creating an OpenAI account and generating an API key.
- Creating a project in Pinecone and obtaining the index, environment, and API key information.
Steps:
- Click the Connection tab and then Create your first connection button.
- Proceed with Select an existing source option and choose Sentry from the list. This indicates that no re-configuration is required until necessary changes are made.
- The next step involves setting up a destination.
- Search for the Pinecone connector and click on it.
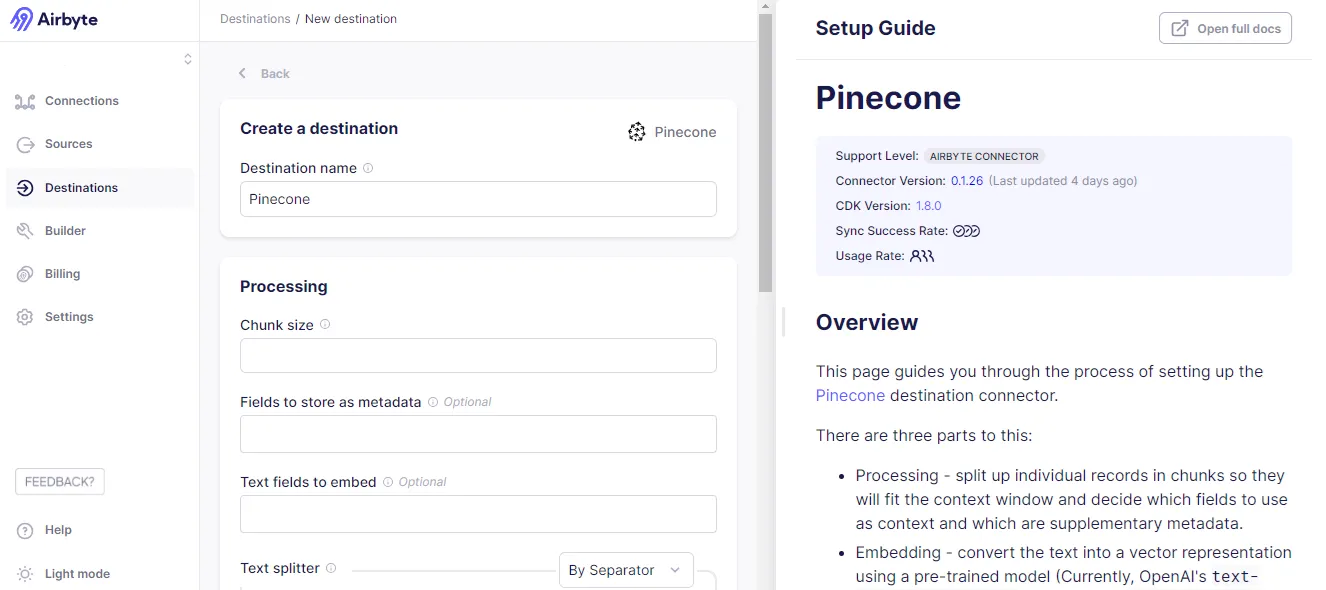
- Start the Pinecone configuration by initially specifying the Chunk size. This processing step will help split the large datasets in Sentry into small tokens.
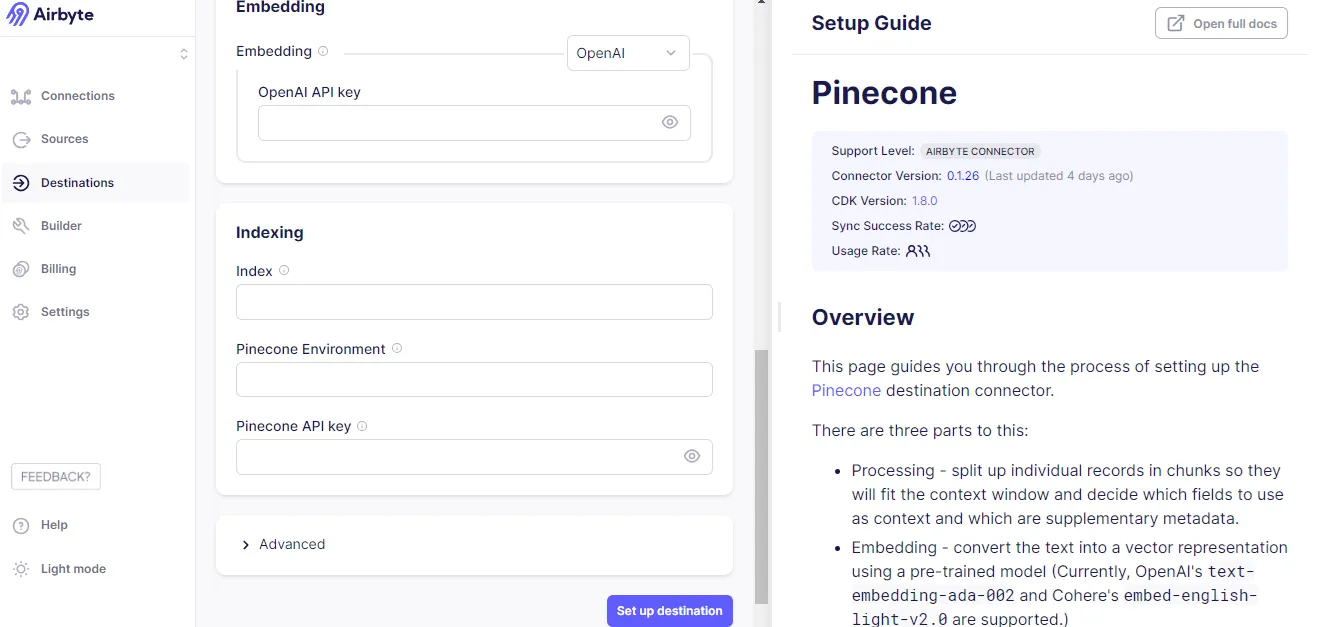
- Then, filling the OpenAI API key to generate vector embeddings allows AI workflows to understand and interpret the data quickly.
- Under Indexing, fill in the index, Pinecone Environment, and Pinecone API key fields to allow the storage of embeddings in the Pinecone database. For more information, users can go through the setup guide.
- After specifying all the mandatory information, click the Set up destination button.
- Select or deselect the required streams and click the Next button.
- Click the Finish and Sync button to establish a connection between Sentry and Pinecone for data transfer.
This example demonstrated how, with Airbyte, you can automate configuring data pipelines and creating custom connectors using AI assistants. It supports several vector databases, such as Chroma, Milvus, and Pinecone, to streamline GenAI workflows and provides automatic chunking, embedding, and indexing features for RAG transformations.
Airbyte’s automation capabilities help convert raw data from Sentry into a format best suited for LLM applications and other AI applications. This reduces complexity and streamlines downstream data analytics and reporting.
Conclusion
Understanding the Airbyte vs Prefect differences enables you to make a good decision that suits your needs. With pre-built connectors and custom connector builder features, Airbyte helps you quickly build data pipelines for data integration requirements. In contrast, Prefect allows you to orchestrate pipelines with the support of Python scripts.
Airbyte is a good choice if you need an excellent solution for your workflow automation compared to Prefect. Prefect is language-specific and heavily depends on coding to orchestrate your workflows. Conversely, Airbyte provides flexible ways to deploy and an easy-to-use interface that enables even people with no technical background to build pipelines.
However, you can evaluate several factors highlighted in this comprehensive guide, focusing on each tool’s ability to handle complex data workflows to make the right decision. The best approach to meeting your data management needs is to combine the strengths of Airbyte and Prefect to create and orchestrate data pipelines.
Want to know the benchmark of data pipeline performance & cost?
Discover the keys to enhancing data pipeline performance while minimizing costs with this benchmark analysis by McKnight Consulting Group.
Get now

Airbyte and Prefect are two comprehensive tools to help you streamline the development and management of scalable data pipelines. While Airbyte allows you to simplify the data integration process, Prefect offers a workflow orchestration solution to enable you to automate and manage data pipelines. Whether you are focusing on data integration or orchestration, understanding their distinct features will help you choose the right tool for your needs.
In this article, you’ll learn the key differences between Airbyte vs Prefect. Let’s get started!
Airbyte: A Brief Overview
Airbyte is an AI-powered data movement and replication platform. Its 550+ pre-built connectors help you simplify data migration from multiple sources to your desired destination, often a data warehouse, lake, or other analytical tools.
If you can’t find the required Airbyte-native connector, you can create one using a low-code connector development kit (CDK) or no-code connector builder. This gives you the flexibility to meet your specific migration needs.
Airbyte also supports destination connectors for vector databases like Pinecone, Milvus, and Weavite, enabling faster AI innovation without compromising data privacy or control. Over 20,000 data and AI practitioners are using Airbyte to handle varied data and make AI actionable across various platforms.
Key Features of Airbyte
- Schema Change Management: Once you configure these settings during the connection setup, Airbyte automatically checks for source schema changes right before syncing. For cloud users, schema checks occur at a maximum frequency of every 15 minutes per source, and for self-hosted users, once every 24 hours. You can also manually refresh the database schema whenever you want.
- Terraform Provider: Airbyte’s Terraform provider enables you to automate and version control your Airbyte source, destination, and connection configuration as code. This helps you save time handling Airbyte resources and working on connector setup with your team members. Terraform Provider is now accessible to users on Airbyte Cloud, self-managed community (OSS), and self-managed enterprise versions.
- Improved Data Syncing and Error Handling: With the launch of Airbyte Destinations V2, you can sync and manage data destination tables efficiently. The new features offer one-to-one mapping, where each stream corresponds to a single table in the destination rather than multiple sub-tables. This helps you improve error handling by preventing typing errors from interrupting the sync. To track and resolve the errors, you can easily identify them in a new _airbyte_meta_column.
Prefect: A Brief Overview
Prefect is a workflow orchestration tool that enables you to develop, monitor, and react to resilient data pipelines using Python code. You can convert any Python script into a dynamic production-ready workflow with a Prefect flow and task components.
Flows in Prefect are Python functions that allow you to accept inputs, perform workflow logic, and return an output. By adding a @flow decorator to your code, you can create a user-defined function in a Prefect flow.
Along with Prefect flow, you can define tasks for each operation within a data workflow using a @task decorator. This can include extraction, transformation, loading, API calls, logging, or any other action that you want to perform. These tasks can be orchestrated by calling it inside the flow function to turn your large-scale Python workflows into an automated, scalable pipeline.
Key Features of Prefect
- Retries: Unexpected errors can happen in your workflows. Prefect enables you to retry flow runs on failure automatically. To activate this feature, you can simply pass an integer to the flow’s retries parameter. When a flow run fails, Prefect helps you retry it up to the specified number of times. If the flow run stops after the final entry, Prefect will enable you to mark the last flow run state as failed.
- Task Caching: Caching in Prefect helps a task skip running its code if it has already been completed. It helps you use the results from the last time the task ran. This saves time and resources for tasks that require a lot of time to compute and ensures your pipelines are consistent when retrying them due to failures.
- Audit Cloud Activity: Prefect Cloud offers audit logs to help you enhance compliance and security. These logs allow you to track user actions such as workspace access, login activity, API key management, account changes, and billing updates. With audit logs, you can understand the cloud activities you performed, when, and using what resources.
Compare Airbyte's pricing to other ELT tools

1 minute cost estimator
What our users say

Apostol Tegko
Data Lead

Extensibility to cover all your organization’s needs
Airbyte has become our single point of data integration. We continuously migrate our connectors from our existing solutions to Airbyte as they became available, and extensibly leverage their connector builder on Airbyte Cloud.
Check the success story

Chase Zieman
Chief Data Officer

Reliable infrastructure to power your own product
Airbyte helped us accelerate our progress by years, compared to our competitors. We don’t need to worry about connectors and focus on creating value for our users instead of building infrastructure. That’s priceless. The time and energy saved allows us to disrupt and grow faster.
Check the success story

Alexis Weill
Data Lead

Extensibility, scalability and no vendor lock-in
We chose Airbyte for its ease of use, its pricing scalability and its absence of vendor lock-in. Having a lean team makes them our top criteria.
The value of being able to scale and execute at a high level by maximizing resources is immense
Check the success story