Before joining Airbyte, I worked at a few companies building Machine Learning teams. What I loved the most from my days as a Data Scientist was helping business teams extract insights from data to attain business impacts, the “sexiest job of the 21st century ” as it was coined in 2012. I participated in expanding teams from various “data maturity” stages, and like many others, I struggled and often got disappointed with what happens when you hire a Data Scientist without a Data Engineer .
Then, with 2020 and the world going on lockdowns, I felt it was not a great time to start a brand new management role if I couldn’t have as many face-to-face interactions. Instead, I joined Airbyte as a software engineer individual contributor. Putting my data science endeavors on hold, I helped build an open-source data integration tool from its early stage with a very small team of talented engineers. I viewed this as an opportunity to lay solid technical and strategic foundations for what I believe would contribute to shaping my view of an ideal data organization , which I am now going to share with you.
At the same time, I would also like to discuss how adding data tools such as Airbyte to your data stack contributes to redefining the roles of Data Engineers, Analysts, Scientists, etc, and the dynamics of the data team with the rest of the company.
The responsibilities of a data team After a year and the world slowly re-opening again, it was now time for me to switch back to my previous management responsibilities and build the Data Analytics team. At that time, Airbyte has grown to more than 150+ data connectors, grew our open-source community of 8k users on Slack, and convinced some of the world’s top investors to fuel our growth even more with $150M Series B . The company is fully remote, with colleagues distributed over 12 countries and 21 US states.
More importantly, we focused our efforts on building a robust plan to solve the data movement problem, which is at the base of the data science hierarchy of needs , a popular concept introduced by Monica Rogati in 2017 . It was now time for me to move to higher layers in the data pyramid of data needs!
Inspired by The AI Hierarchy of Needs I agree with Hugh Williams that it is more inclusive to use the term “pyramid” instead of “hierarchy” because the roles “on top” don’t necessarily mean that it’s “better” than the ones at “the bottom”, they are just different responsibilities and can be staffed differently. These roles can indeed be split into narrower positions or covered by the same person depending on the maturity state and size of your organization.
Inspired by the The Pyramid of Data Needs However, the narrative stays the same, and as Maslow explained in his representation, you need to fulfill the required bottom needs before addressing needs from a higher layer. Hence, in terms of staffing, a sound recommendation for a few years now is to hire technical Data Engineers before onboarding more Data Analysts or Scientists on the team (which is not necessarily what was actually being done in the industry).Of course, in either case, you’ll find it easier to fulfill your staffing needs by recruiting remotely — hiring in India , either directly or through a recruiting firm , for example, if you’re struggling to source homegrown talent.
The dynamics of a data team As a result, a reasonable suggestion in the data space was to thrive for an ideal ratio of 2-3 Data Engineers for each Data Scientist or Data Analyst.
Data Engineers play a support role for others on the team and represent the often overlooked iceberg part that never goes into the spotlight. This composition would allow Data Engineers to “carry” (like the rodent carrying the smaller one on its back in the image below) more comfortably projects, analyses, prototypes, or experimentations to production. Having a good ratio of Data Engineers would help avoid accumulating large amounts of technical data debts in a data lake , converting it into a “data swamp”.
The impact of modern data tools on the Data Engineer role I strongly resonate with the highly-quoted thoughts shared by Jeff Magnusson in his article from 2016 that engineers shouldn’t write ETL which advocates for sacrificing technical efficiency for velocity and autonomy as a means to reduce the vicious cycle of frustration building up in traditional data teams.
Like many others, the data community agrees today that tools and frameworks (especially open-source ones!) should automate the boring parts of the ETL process , which means these repetitive tasks that used to be falling under the Data Engineering scope of responsibilities would be easier to manage moving forward. The rise of the Data Engineer and downfall of the Data Engineer by Maxime Beauchemin discusses how the role of the Data Engineer is changing in more detail.
He noticed Data Engineers started to add more data tools to their stack, start using more abstractions, and finally agreed on a set of common best practices when building data pipelines. Today, data orchestrators such as Airflow (which Maxime started during his time at Airbnb) are sprouting (Prefect, Temporal, Dagster, …) and are replacing the need to write custom orchestration logic. But this trend does not stop here!
Data integration tools like Airbyte are handling the ingestion challenges of integrating data from an infinitely diverse catalog of data sources with a never-ending tendency to evolve and change their API interface over time. Reverse ETL tools such as Grouparoo (acquired by Airbyte ), Hightouch, Census, etc… are easing the need to synchronize your operational systems.
The emergence of modern data tools doesn’t mean we can completely retire the Data Engineer position and replace it with tools. That’s not how automation works! Sometimes it might still be more efficient to write that little custom ETL script , but maybe only the Data Engineers would feel confident about authoring and maintaining it. On the other hand, for someone that is not so technically confident as a Data Engineer, it’s easier and safer to use a tool that abstracts it away. But bear in mind, that sometimes the tool will not do what you expect, so it’s still very important to understand how it works and have the ability to debug, patch, and contribute back to the community by correcting and enhancing data tools .
The bottom line is that Data Engineers can now divert their focus to different tasks, more generalized and more analytical , while the rest of the data gang such as Data Scientists, Analytics Engineers, Data Analysts, Product Managers, or Business Analysts can also more easily jump in and deploy solutions from the traditional “Data Engineering” scope. Because it is easier to blur the technical boundaries (thanks to tools and frameworks), we shift away from the standard siloed hot potato dynamic to an environment where everybody on the data team has a wider autonomy and more chances to collaborate .
The ability to cover the Data Science Pyramid of needs is better shared and everybody becomes more “full-stack”, which translates into more velocity for the team and more control on owning the outcomes , one of the values that we want to nurture at Airbyte. Another advantageous aspect is that we can promote richer diversity of backgrounds in the team while mix-matching one another strengths and weaknesses.
The data mindset for execution Now that we’ve seen how to assist your team with the bottom layers of the Data Science pyramid with more tooling, let’s zoom on the middle and upper layers.
Your organization needs to be good at monitoring the present and it requires to properly reflect on what happened in the past before tackling work on complex models for predicting the future . In other words: “learn to walk before starting to run”.
As a data team, you will most likely juggle two objectives: deliver insights fast and consolidate what you built so far. To accomplish this, I’ve found it helpful to focus on two heuristics: K-I-S-S and D-R-Y.
If you follow the K-I-S-S (Keep It Simple, Stupid) heuristic , abide by agile principles, and regularly iterate with stakeholders, it will lead to more immediate business impacts. Good enough is always appropriately quicker to come up with than perfect.
If you follow the D-R-Y (Don’t Repeat Yourself) heuristic , for example, refactoring an existing data pipeline into something stronger, you will more easily attain a single source of truth from which you can build more leverage.
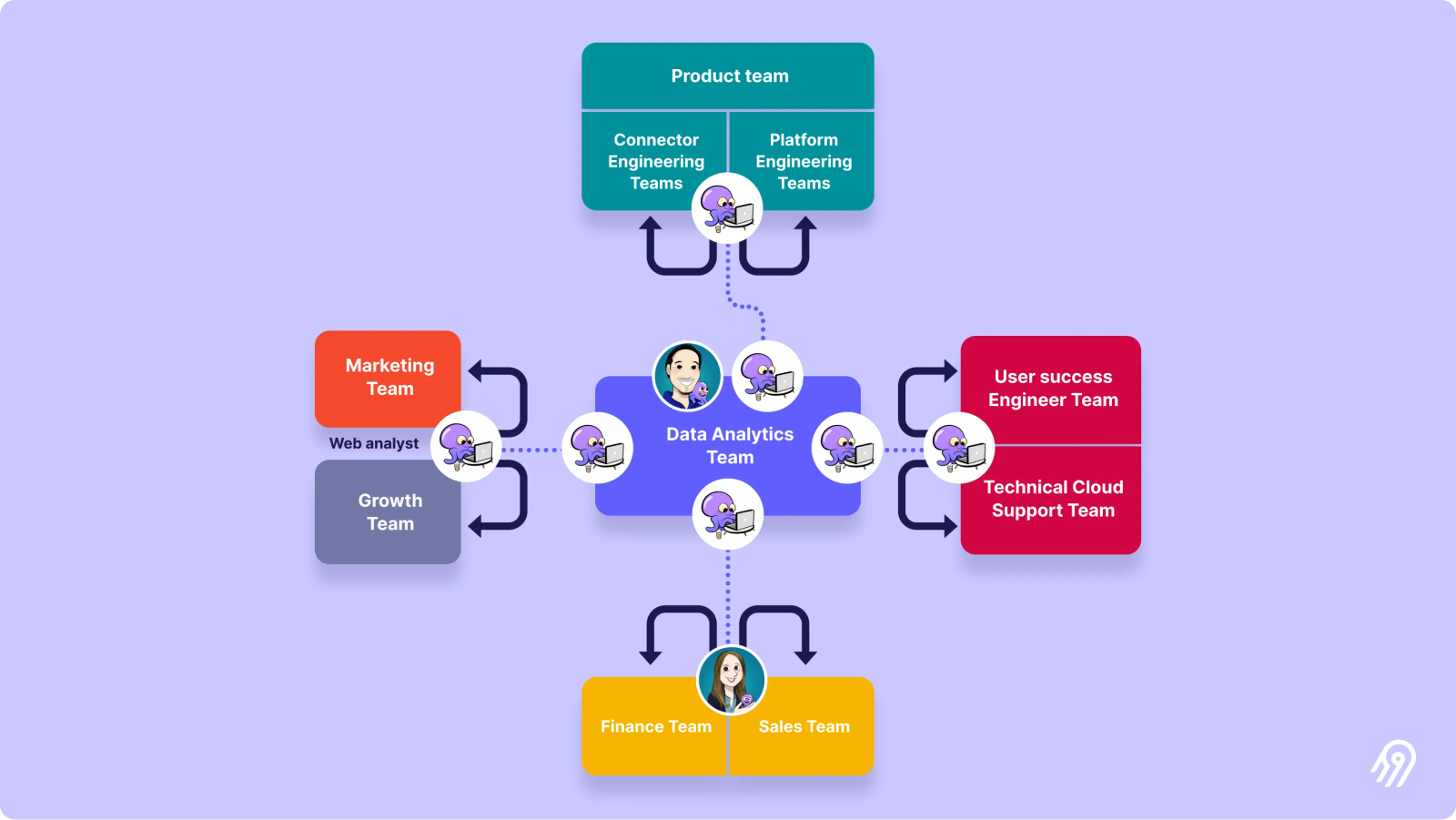
The structure of the Airbyte data team I officially transitioned from being a software engineer at Airbyte to focusing on the internal data stack and team in April 2022. I started my work by mapping out all the tools and processes that we started to use organically by different teams within Airbyte. I then started to consolidate all this infrastructure into a more coherent “modern data stack ”, centralized and versioned controlled, leaning towards Open-Source Software. Today, we are using BigQuery as our data warehouse , Airbyte Cloud as our data integration tool, dbt to transform and consolidate data, and Metabase for data insights. The growing team is soon working on adding a data orchestration tool , a data quality tool, and trying to get as much infrastructure as code as possible.
At the same time, while reworking the backbone of our data stack, we have to make improvements on the front-end of Analytics too. However, with the current state of the data team, we can only cover a few domains at once while other teams self-serve themselves.
After reviewing the different data needs from the various teams and departments to be kept top of mind, we would like to grow enough data hands to be able to dedicate at least one team member per domain: product & engineering, open-source & cloud support, marketing & growth, and finance & sales.
In the long term, it would be ideal to reach a point where we can embed data profiles into business team routines while keeping some hands on deck in the central data team to re-work some of the projects as they get built . Keeping that re-work smooth as data profiles move between squads leans heavily on the basics of project management , which give the central team a shared way to hand off and track work. The aim is to share some bandwidth to accomplish both objectives of prototyping and consolidating each business function in a continuous manner.
The structure of the growing Airbyte data team That’s why it’s probably required to have at least two-person squads, so they can swap seats while cycling through the experimenting and building phases . Note that I would also advocate for these pods with a balanced mix between more technical-oriented versus business-oriented professionals (Data Analyst vs Data Engineers, or hybrid profiles such as analytics engineers), so they can function in a more autonomous and distributed manner. This is why we are currently hiring at least two senior Data Engineers in the short term that can function as Analytics Engineers and will be slowly adding more with time.