Data consumers, such as data analysts, and business users, care mostly about the production of data assets. On the other hand, data engineers have historically focused on modeling the dependencies between tasks (instead of data assets) with an orchestrator tool. How can we reconcile both worlds?
This article reviews open-source data orchestration tools (Airflow, Prefect, Dagster) and discusses how data orchestration tools introduce data assets as first-class objects. We also cover why a declarative approach with higher-level abstractions helps with faster developer cycles, stability, and a better understanding of what’s going on pre-runtime. We explore five different abstractions (jobs, tasks, resources, triggers, and data products) and see if it all helps to build a Data Mesh.
What Is Data Orchestration? Data Orchestration models dependencies between different tasks in heterogeneous environments end-to-end . It handles integrations with legacy systems, cloud-based tools, data lakes , and data warehouses . It invokes computation , such as wrangling your business logic in SQL and Python and applying ML models at the right time based on a time-based trigger or by custom-defined logic .
What makes an orchestrator an expert is that it lets you find when things are happening (monitoring with lots of metadata), what is going wrong and how to fix the wrong state with integrated features such as backfills.
When discussing complex open-source cloud environments, it's crucial to integrate and orchestrate various tools from the Modern Data Stack (MDS) and automate them as much as possible as companies grow their need for orchestration. With ELT getting more popular, data orchestration is less about data integration but more about wrangling data with assuring quality and usefulness. Previously, it was common among data engineers to implement all ETL parts in the orchestrator, typically with Airflow . On top, monitoring, troubleshooting, and maintenance become more apparent, and the need for a Directed Acyclic Graph (DAG) of all your tasks arises. DAGs allow us to describe more complex workflows safely .
In the end, an orchestrator must activate Business Intelligence, Analytics, and Machine Learning . These are company-accessible dashboards/reports, machine learning models, or self-serve BI environments where users can create and pull their data. It is also where the shift happens from data pipelines to what the user is interested in, the Data Asset or Data Product, to use the jargon of Data Mesh .
📝 I will use orchestration as a synonym for data orchestration, as all we talk about in this article is data. As well, I use Data Assets interchangeably with Data Products .
Alternatives to Data Orchestration By now, we have a pretty good understanding of data orchestration . Let’s discuss the main alternative to data orchestration. It’s called choreography, and as opposed to orchestration, it does not take care of the whole process. Instead, it sends and communicates events to a specific message storage. Choreography is similar to a microservice, where each application only knows how to do its core function.
As always, both have their advantages and disadvantages. For example, in the orchestration part, you have a unified view—the control plane —where choreography is loosely coupled, and the shared-nothing pipelines can be very hard to manage. On the other hand, a choreographic architecture is easier to scale , although Kubernetes can also help to scale the orchestration part.
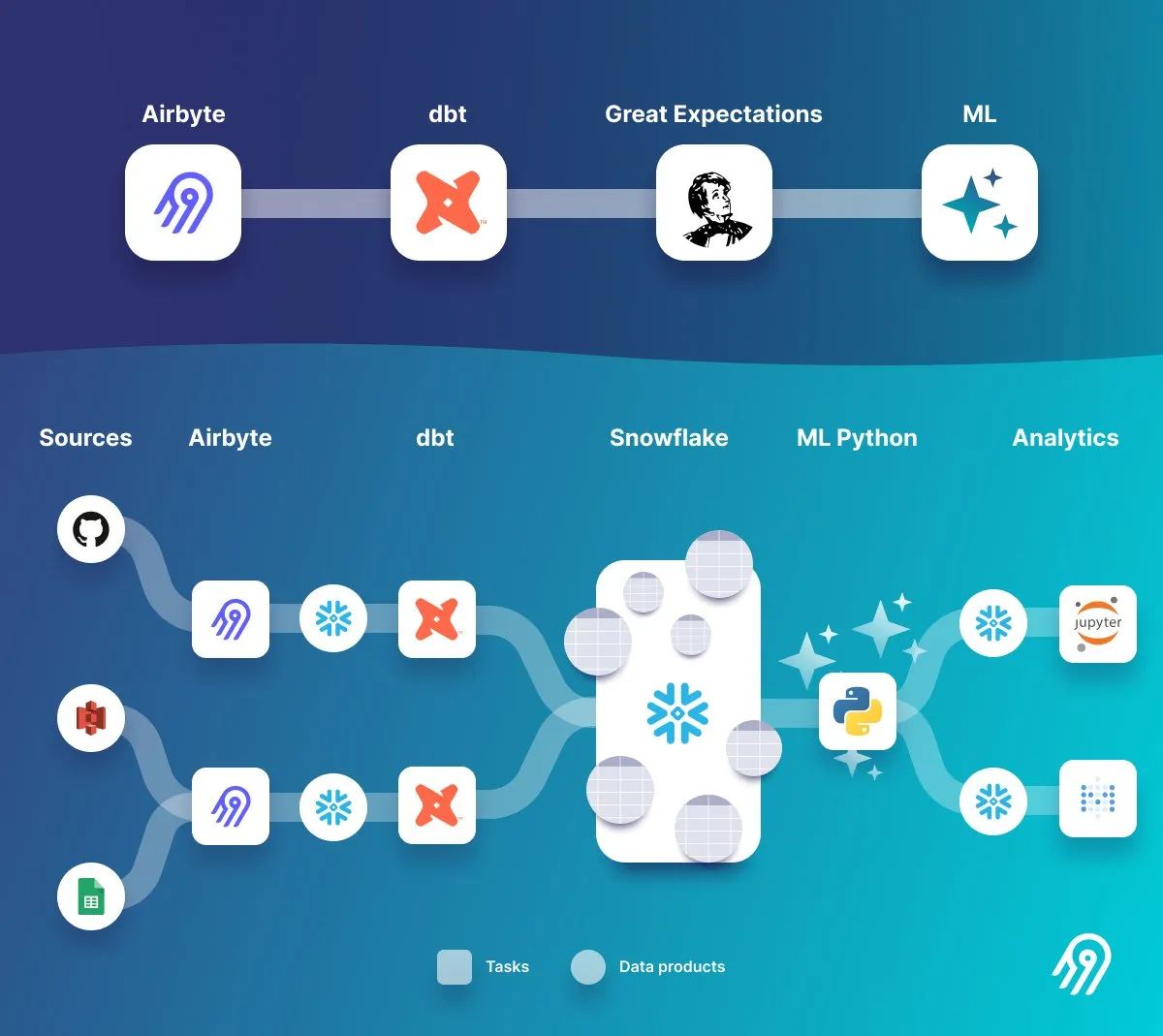
The Shift From a Data Pipeline to a Data Product In the era of big data, we have managed to compute massive amounts of data with high-scale computation and storage and efficiently query data sets of arbitrarily large size. But as a side effect, data teams are growing fast, and so do new data sources daily, creating more complex data environments. Although each data project starts simple, below is an example illustrating a typical data architecture among data engineers.
An example of a typical cloud data project that needs data orchestration The questions are not anymore how we can transform data overnight or create a DAG with a modern data orchestrator, but how we get an overview of all data crunched and stored. How do we do that shift?
There are several trends to support this:
Think about data as a product with data-aware pipelines that know about the inner life of a task Shift to declarative data pipeline orchestration Use abstractions to reuse code between complex cloud environments Make Python a first-class citizen with a functional data engineering approach and idempotent functions. Applying this will help you get the Data Product Graph view we are all longing for. Let’s have a look at each of these trends.
Data Products Are the Output of Modern Orchestration One solution to achieve the shift is to focus on the data assets and products with excellent tooling by fading the technology layer to the background and giving access to the data products to data consumers. With Data Mesh popularized Data as a Product , we will next see how can we apply this change to data orchestrators. Seeing the data as the use-case, the data product each data consumer wants has a clearly defined owner and maintainer.
In the end, all data must come from somewhere and go somewhere . Modern data pipeline orchestrators are the layer that interconnects all those tools, data, practitioners, and stakeholders.
A data asset is typically a database table, a machine learning model, or a report — a persistent object that captures some understanding of the world. Creating and maintaining data assets is the reason we go through all the trouble of building data pipelines. Sandy Ryza on Introducing Software-Defined Assets But how do we achieve such a shift to data products? We can use a declarative approach and abstractions that we know ahead of runtime . This way, we can declare and interact with them the same way we do with tasks and pipelines. We can show the Data Lineage of upstream assets - not tasks or pipelines. The actual data asset makes it easy to understand for anyone, for example, if a business logic changes or new data of an upstream asset arrives.
Achieving this shift from a pipeline to a business logic-centric data product view is a challenging engineering problem with data ingesting from dozens of external data sources, SaaS apps, APIs, and operation systems. At Airbyte, we know that pain firsthand and built all of these connectors to mitigate the E(xtract) and L(oad) and difficult Change Data Capture (CDC) part.
ℹ️ The data product does not need to live inside the orchestration tool. The orchestrator manages only the dependencies and business logic. These assets are primarily tables, files, and dashboards that live somewhere in a data warehouse, data lake, or BI tool.
💡 A handy side-effect if you use mostly one orchestrator is that you can have a data product catalog inside the orchestrator. It gives you valuable information about when this particular data product was updated last, by who, and which upstream assets have changed. This information probably goes into a so-called Data Catalog in the long run.
Declarative Pipelines Are Taking Over Imperative Pipelines Similar to how DevOps changed how software gets deployed with Kubernetes and descriptive YAML , the exact same should happen with data pipelines for faster developer cycles, better stability, and a better understanding of what’s going on pre-runtime.
In short, an imperative pipeline tells how to proceed at each step in a procedural manner. In contrast, a declarative data pipeline does not tell the order it needs to be executed but instead allows each step/task to find the best time and way to run. The how should be taken care of by the tool, framework, or platform running on. For example, update an asset when upstream data has changed. Both approaches result in the same output. However, the declarative approach benefits from leveraging compile-time query planners and considering runtime statistics to choose the best way to compute and find patterns to reduce the amount of transformed data.
Declarative vs. Imperative Overview Declarative approaches appeal because they make systems easier to debug and automate. It's done by explicitly showing intention and offering a simple way to manage and apply changes. By explicitly declaring how the pipeline should look, for example, defining the data products that should exist , it becomes much easier to discover when it does not look like that, reason about why, and reconcile. It's the foundation layer for your entire platform's lineage, observability, and data quality monitoring.
Abstractions: Jobs, Tasks, Resources, Triggers Why abstractions, and how do they help us define Data Products? Because of higher-level abstractions, we are more explicit and declarative.
Lots of the ability to manage data products comes from Python being a first-class citizen in the modern data stack. In The Rise of the Data Engineer , Maxime said code, in our case, a dedicated function is the best higher-level abstraction for defining a software construct (automation, testability, well-defined practices, and openness). It declares upstream dependency in-line in a Pythonic open API, with abstracted authorship on top of assets with a Python function.
So what abstractions do we have as of today? For example, let's take the resource abstraction (Dagster , Prefect , referred to as an operator in Airflow ). You abstract complex environments and connections away with a simple construct like that. You have the immediate benefits of defining that once and using it in every task or pipeline with `context.resources.pyspark`, e.g., for Spark using Dagster. Through that, the code is battle-tested and used the same everywhere. As it's a concrete construct, you can unit test the heck out of it—which is a tricky thing otherwise. Think of databricks notebooks. The hassle of which secrets, hostname, and configs (e.g., a Spark cluster has thousands of them) are done once, and you do not need to think about it when creating transformations.
An example of defining a resource once and re-use everywhere (tasks, pipelines, assets) with `context.resources.pyspark.*` (source on GitHub)
Another abstraction is tasks (Airflow , Dagster , Prefect ) that let you build pipelines like Lego blocks. Everyone creates tasks, and you choose the one you need to make your DAG . Data engineers could write stable, high-quality battle-tested tasks, and analytics or machine learning engineers could use them, which is a dream for reusability and following the DRY principle.
Triggers (Prefect , Dagster , Airflow ) are another one. They can be time, typical cron example `0 8 * * *` for a daily schedule at 8 AM or event-based such as a new file to an S3-folder, new data arrived at the API. More abstractions we will not go into are config systems , data types, IO management, and repositories . These can add to each part of the above abstraction.
Abstractions let you use data pipelines as a microservice on steroids . Why? Because microservices are excellent in scaling but not as good in aligning among different code services. A modern data orchestrator has everything handled around the above reusable abstractions. You can see each task or microservice as a single pipeline with its sole purpose—everything defined in a functional data engineering way. You do not need to start from zero when you start a new microservice or pipeline in the orchestration case.
There is one more key abstraction, data products (Dagster ) or data assets that are newer and not get generalized among all orchestrators. We will discuss this abstraction in more detail next.