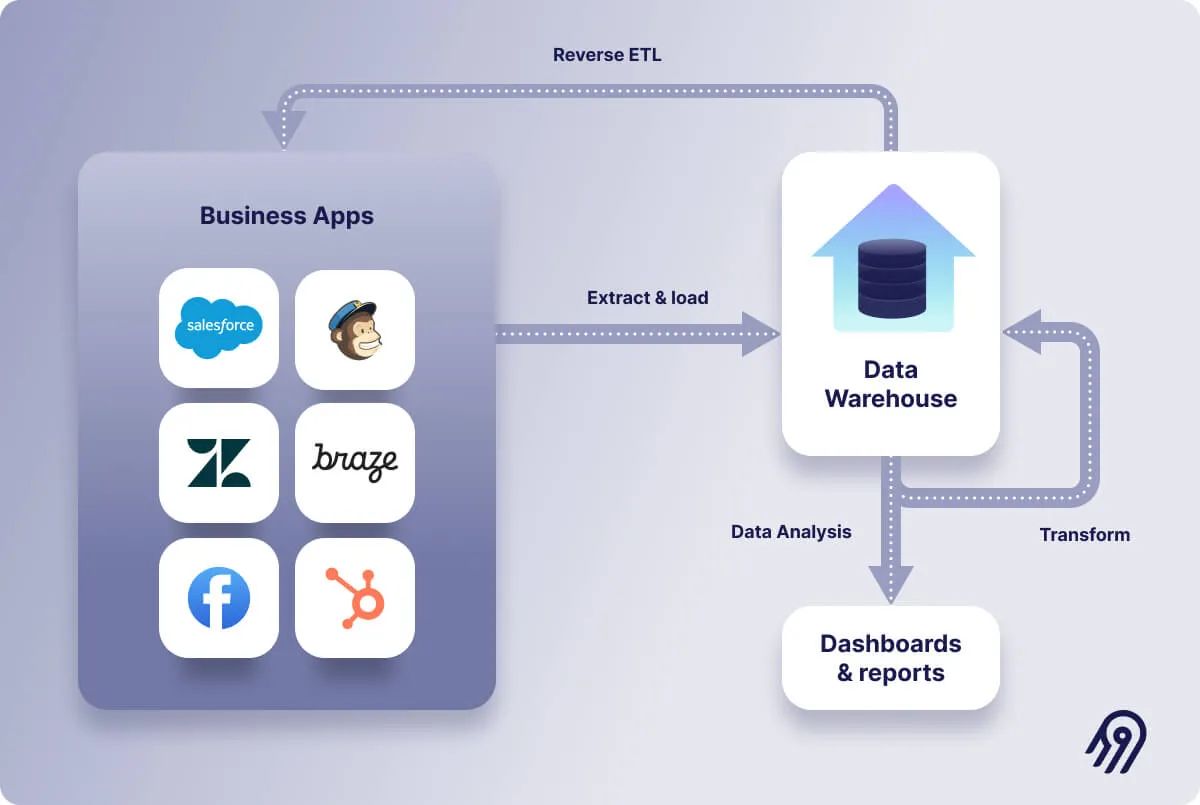
Data teams increasingly use ETL pipelines to move data from a warehouse into business applications. The concept, known as "Reverse ETL," is rapidly becoming a standard component of data stacks.Reverse ETL Keep reading to learn more about Reverse ETL, why it’s technically different from traditional ETL, and the most prevalent use cases.
Evolution of Data Integration: From ETL to ELT The data engineering world is constantly evolving, especially regarding data integration implementations.
First, we had the ETL (extract, transform, load) approach to data pipelines, which essentially involves extracting data from different sources, transforming it, and loading it into – most commonly – a data warehouse where it can be used as a source of dashboards and reports.
ETL is a classic paradigm (it emerged in the 1970s!). Recently, it has shifted to ELT (extract, load, transform). The ELT philosophy dictates that data should be untouched – apart from minor cleaning and filtering – as it moves through the extraction and loading stages so that the raw data is always accessible in the data warehouse.
In an ELT pipeline, data enrichment and transformation occur inside the data warehouse, not in a processing server like in the case of ETL pipelines. The shift has been primarily made possible thanks to the appearance of cloud-based data warehouses like Redshift, BigQuery, or Snowflake.
The qualities described above make ELT pipelines more adaptable, efficient, and scalable than ETL pipelines , particularly when integrating massive amounts of data, processing structured and unstructured data, and enabling different types of data analytics and data science.
But the rise of the ELT paradigm does not mean that ETLs have been completely replaced. Some situations require transformations before data lands anywhere, for example, to handle personal identifiable information (PII) (which often involves removing, masking, or encrypting data fields).
Don't forget to explore the article on ETL vs. ELT for further insights into these essential data integration processes!
Emergence of Reverse ETL Reverse ETL is the flip side of the ETL/ELT.With Reverse ETL, the data warehouse becomes the source rather than the destination . Data is taken from the warehouse, transformed to match the destination's data formatting requirements, and loaded into an application – for example, a CRM like Salesforce – to enable action.
Reverse ETL is the process of syncing data from a source like a data warehouse to a business application so it can be used by marketing, sales, support, and other teams in the tools they use. Hence, a Reverse ETL “operationalizes” data throughout an organization by putting data back into business applications. In that sense, a Reverse ETL is not something that comes to replace the ETL or ELT data pipelines; it’s instead used in conjunction as part of a data stack.
In a way, the Reverse ETL concept is not new to data engineers, who have been enabling data movement warehouses to business applications for a long time. As Maxime Beauchemin mentions in his article , Reverse ETL “appears to be a modern new means of addressing a subset of what was formerly known as Master Data Management (MDM).”
But why can't data engineers use conventional solutions to move data out of the warehouse into business applications? Isn’t it as easy as reversing the arrow from application -> warehouse to warehouse -> application? Well, it turns out that Reverse ETL is way more challenging to get right than conventional ETL/ELT . Let’s see why.
Why Reverse ETL Matters? In today's data-driven landscape, Reverse ETL emerges as a pivotal solution, offering businesses the means to bridge the gap between data analytics and operational workflows. Here's why Reverse ETL matters:
Data Democratization: Reverse ETL empowers non-technical users across departments to access and utilize data from the central warehouse effectively. This democratization of data fosters collaboration and enables informed decision-making at all levels of the organization.Real-time Insights: By enabling the seamless flow of data from the warehouse to business applications , Reverse ETL facilitates real-time insights. This allows organizations to react promptly to changing market conditions, customer needs, and operational challenges.Enhanced Business Agility: With Reverse ETL, organizations can quickly adapt to evolving business requirements and market dynamics. By ensuring data accessibility and integration with critical business applications, Reverse ETL enables agile decision-making and strategic responses.Improved Operational Efficiency: Reverse ETL streamlines data workflows by automating the movement of data from the warehouse to operational systems. This automation reduces manual intervention, minimizes errors, and enhances operational efficiency.Personalized Customer Experiences: Reverse ETL enables organizations to deliver personalized customer experiences by integrating customer data with marketing, sales, and support systems. This integration allows for targeted communications, tailored product recommendations, and proactive customer support.Avoiding Data Silos: Data silos pose a significant challenge for organizations, hindering collaboration, inhibiting insights, and impeding innovation. Reverse ETL plays a crucial role in dismantling these silos by facilitating bidirectional data movement between analytical environments and operational systems. By breaking down barriers and enabling seamless data integration, Reverse ETL fosters a holistic view of organizational data, empowering stakeholders to derive actionable insights and drive informed decision-making. Empowering Non-Technical Users: Traditionally, data integration and transformation have been the domain of technical experts, requiring specialized skills and expertise. Reverse ETL democratizes data access and empowers non-technical users to leverage data for decision-making. By providing intuitive interfaces, self-service capabilities, and pre-built connectors, Reverse ETL platforms enable users across the organization to extract value from data without reliance on IT or data engineering teams. This democratization of data empowers stakeholders at all levels to harness insights, drive innovation, and contribute to organizational success.Key Technical Distinctions of Reverse ETL Key Technical Distinctions Description Data Connectors Reverse ETL platforms utilize a wide range of connectors to interact with diverse data sources and destinations. These connectors facilitate seamless integration with popular analytics platforms, data warehouses, SaaS applications, and operational systems, ensuring compatibility across the data ecosystem. Transformation Capabilities Reverse ETL emphasizes transformation within the operational context, focusing on data enrichment, normalization, and validation. This ensures consistency and accuracy across operational systems, enabling organizations to derive actionable insights from integrated data. Scalability and Performance Reverse ETL solutions are designed for robust scalability and performance, capable of handling large volumes of data and meeting stringent latency requirements in dynamic operational environments. Efficient data processing, parallelization, and optimization techniques ensure optimal performance at scale. Monitoring and Governance Effective governance and monitoring are integral to Reverse ETL, enabling organizations to maintain data integrity, compliance, and security. Comprehensive auditing, logging, and alerting mechanisms track data lineage, monitor data quality, and detect anomalies in real-time, ensuring data reliability.
ETL vs. Reverse ETL When considering ETL approaches versus Reverse ETL , it seems logical that ETL methods should seamlessly apply to Reverse ETL . Both deal with the transfer of data to and from systems like Zoominfo Salesforce , Mailchimp , Snowflake , or BigQuery . However, as noted by Brian Leonard , founder of Grouparoo , a Reverse ETL company recently acquired by Airbyte , "To read from Zendesk , you have to know about Zendesk . To write to Zendesk , you have to know about Zendesk . But generally, writing to an API is harder than reading from it."
The real challenge of Reverse ETL emerges when attempting to send data to a business application via an API, a task made difficult by the plethora of business applications utilized by companies today. Brian further highlights the challenges of implementing Reverse ETL for multiple destinations, stating, "Handling the one-by-one nature of it is challenging."
Synchronization Mode In the world of data integration, synchronization mode dictates how data moves from its source to its destination. Within ETL/ELT processes, two primary modes exist: full and incremental data extraction.
Full Data Extraction: This method retrieves all data from the source every time it's executed.Incremental Data Extraction: Unlike full extraction, this mode selectively pulls only new or updated records since the last synchronization. It's especially useful for managing large datasets efficiently.Benefits of Incremental Extraction:
Handling substantial data volumes becomes more manageable with incremental extraction. It focuses solely on changes since the last synchronization, enhancing performance. Change Data Capture (CDC) techniques play a pivotal role in identifying new and updated data within ETL pipelines. However, implementing CDC in Reverse ETL poses challenges due to the lack of transaction logs or "updated_at" columns in warehouses.
Upsert Operations:
In traditional ETL pipelines, the UPSERT operation merges data into databases or data warehouses, ensuring duplicate entries are avoided. While most databases support UPSERT, APIs often lack this capability. Instead, they utilize separate endpoints for creating and updating records.
Challenges in Reverse ETL:
The absence of upserting mechanisms in APIs adds complexity to Reverse ETL processes. This requires meticulous tracking of data updates and creations. Brian shares insights on managing this complexity, emphasizing the need for comprehensive bookkeeping when dealing with multiple updates and creations in Reverse ETL scenarios.
Data quality & Transformations With ETL, you go from specific to general, meaning that you extract data from different specific sources to then integrate it into a common destination. Writing to a data warehouse is relatively easy since warehouses are designed to store massive volumes of data from several distinct sources. On the other hand, with Reverse ETL, you go from general to specific, having to conform to each business application API.
Because each API has a somewhat different interface, each Reverse ETL pipeline requires specific code. For example, the transformations necessary to transfer data to Mailchimp differ significantly from the ones needed for Salesforce.
Additionally, Reverse ETL pipelines must ensure that data conforms to the API specification, which, in turn, may require more data transformations than traditional ETL.
“For example, in Mailchimp, if you try to write an invalid email address, even if it looks like an email address, it will error. For example, Mailchimp will reject it because it knows it's not a real domain. So there's so much more validation and knowledge of that destination”, says Brian. “You're keeping track of every record a little more than you are in the ELT model. These data validation issues are much less common in the ELT space. ”
Failures & Job Re-Execution ETL pipelines write to data warehouse tables, which means that if there’s any failure, you can technically drop the tables and simply re-execute the ETL job to recover or correct corrupted data.
In Reverse ETL, it might not be as easy. As Brian explains, “Normally, ETL batch jobs are what we call in Computer Science: idempotent functional
Hence, job re-executions need to be handled with more care in Reverse ETL as there may be unwanted side effects.
How does reverse ETL work? The mechanism of reverse ETL includes work in several stages and let us decode that for you;
In reverse ETL, the organization's data is extracted from a data warehouse or any other centralized data storage system. The extraction process usually entails running an SQL query against the data warehouse or using another extraction technique.
💡Suggested Read : Data Extraction Tools
Data Transformation After being extracted, the data needs to be formatted so that it can be loaded into operational databases, SaaS apps, or other business applications. To guarantee compatibility with the target systems, this transformation process may involve cleaning the data, converting data types, aggregating data, and carrying out additional necessary transformations.
Data Loading The transformed data is then loaded into the target systems, which could be other business applications (like ERP systems), SaaS applications (like CRM systems, and marketing automation platforms ), or operational databases (like transactional databases).
Scheduling and Monitoring To make sure that the target systems are always updated with the most recent data from the data warehouse, reverse ETL processes are frequently scheduled to run at regular intervals. For troubleshooting any issues that may arise, monitoring may involve logging, reviewing logs, and setting up alerts.
Data Security In reverse ETL processes, data security plays a crucial role in guaranteeing the protection of sensitive data during the extraction, transformation, and loading stages. To protect data while it's in transit and at rest, reverse ETL tools have encryption, access controls, and other security measures in place.
Customer Data Platform vs. Reverse ETL A Customer Data Platform (CDP) serves as a centralized system for aggregating and storing customer data from various sources. Conversely, Reverse ETL involves the movement of data from a warehouse to business applications. In essence, a CDP represents a platform, while Reverse ETL signifies a process.
CDPs are specialized tools designed to create a unified view of customers by consolidating data from diverse sources. They primarily benefit marketing and sales teams by providing insights into customer behavior and preferences. On the other hand, Reverse ETL is applicable to a broader spectrum of data, not limited to customer data.
The data architecture supporting Reverse ETL centralizes all data in a data warehouse, facilitating its integration with data from other sources for more comprehensive analysis. In contrast, CDPs predominantly offer access to consumer data, restricting the scope of analysis.
While Reverse ETL is a process without a dedicated interface for data activation, relying instead on the interfaces of third-party applications, CDPs provide such interfaces. Therefore, incorporating both Reverse ETL and a CDP into a data stack is often advantageous, leveraging the strengths of each approach.