TL;DR
This can be done by building a data pipeline manually, usually a Python script (you can leverage a tool as Apache Airflow for this). This process can take more than a full week of development. Or it can be done in minutes on Airbyte in three easy steps:
- set up CSV File as a source connector (using Auth, or usually an API key)
- set up Cassandra as a destination connector
- define which data you want to transfer and how frequently
You can choose to self-host the pipeline using Airbyte Open Source or have it managed for you with Airbyte Cloud.
This tutorial’s purpose is to show you how.
What is CSV File
A CSV (Comma Separated Values) file is a type of plain text file that stores tabular data in a structured format. Each line in the file represents a row of data, and each value within a row is separated by a comma. CSV files are commonly used for exchanging data between different software applications, such as spreadsheets and databases. They are also used for importing and exporting data from web applications and for data analysis. CSV files can be easily opened and edited in any text editor or spreadsheet software, making them a popular choice for data storage and transfer.
What is Cassandra
Cassandra is a distributed NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is highly scalable and fault-tolerant, making it ideal for use in big data applications where data needs to be stored and accessed quickly and reliably. Cassandra uses a peer-to-peer architecture that allows for easy distribution of data across multiple nodes, and it supports a flexible data model that can handle structured, semi-structured, and unstructured data. It is widely used in industries such as finance, healthcare, and e-commerce, where real-time data processing and analysis are critical.
Prerequisites
- A CSV File account to transfer your customer data automatically from.
- A Cassandra account.
- An active Airbyte Cloud account, or you can also choose to use Airbyte Open Source locally. You can follow the instructions to set up Airbyte on your system using docker-compose.
Airbyte is an open-source data integration platform that consolidates and streamlines the process of extracting and loading data from multiple data sources to data warehouses. It offers pre-built connectors, including CSV File and Cassandra, for seamless data migration.
When using Airbyte to move data from CSV File to Cassandra, it extracts data from CSV File using the source connector, converts it into a format Cassandra can ingest using the provided schema, and then loads it into Cassandra via the destination connector. This allows businesses to leverage their CSV File data for advanced analytics and insights within Cassandra, simplifying the ETL process and saving significant time and resources.
Step 1: Set up CSV File as a source connector
1. Open the Airbyte platform and navigate to the "Sources" tab on the left-hand side of the screen.
2. Click on the "CSV File" source connector and select "Create new connection."
3. Enter a name for your connection and click "Next."
4. In the "Configuration" tab, select the CSV file you want to connect to by clicking on the "Choose File" button and selecting the file from your local machine.
5. In the "Schema" tab, you can customize the schema of your data by selecting the appropriate data types for each column.
6. In the "Credentials" tab, enter the necessary credentials to access your CSV file. This may include a username and password or other authentication details.
7. Once you have entered your credentials, click "Test Connection" to ensure that Airbyte can successfully connect to your CSV file.
8. If the connection is successful, click "Create Connection" to save your settings and start syncing your data.
9. You can monitor the progress of your sync in the "Connections" tab and view your data in the "Destinations" tab.
Step 2: Set up Cassandra as a destination connector
1. First, navigate to the Airbyte website and log in to your account.
2. Once you are logged in, click on the "Destinations" tab on the left-hand side of the screen.
3. Scroll down until you find the "Cassandra" destination connector and click on it.
4. You will be prompted to enter your Cassandra connection details, including the host, port, username, and password.
5. Once you have entered your connection details, click on the "Test" button to ensure that your connection is working properly.
6. If the test is successful, click on the "Save" button to save your connection details.
7. You can now create a new pipeline and select Cassandra as your destination connector.
8. Follow the prompts to configure your pipeline and map your source data to your Cassandra database.
9. Once you have configured your pipeline, click on the "Run" button to start the data transfer process.
10. You can monitor the progress of your pipeline on the Airbyte dashboard and troubleshoot any issues that may arise.
Step 3: Set up a connection to sync your CSV File data to Cassandra
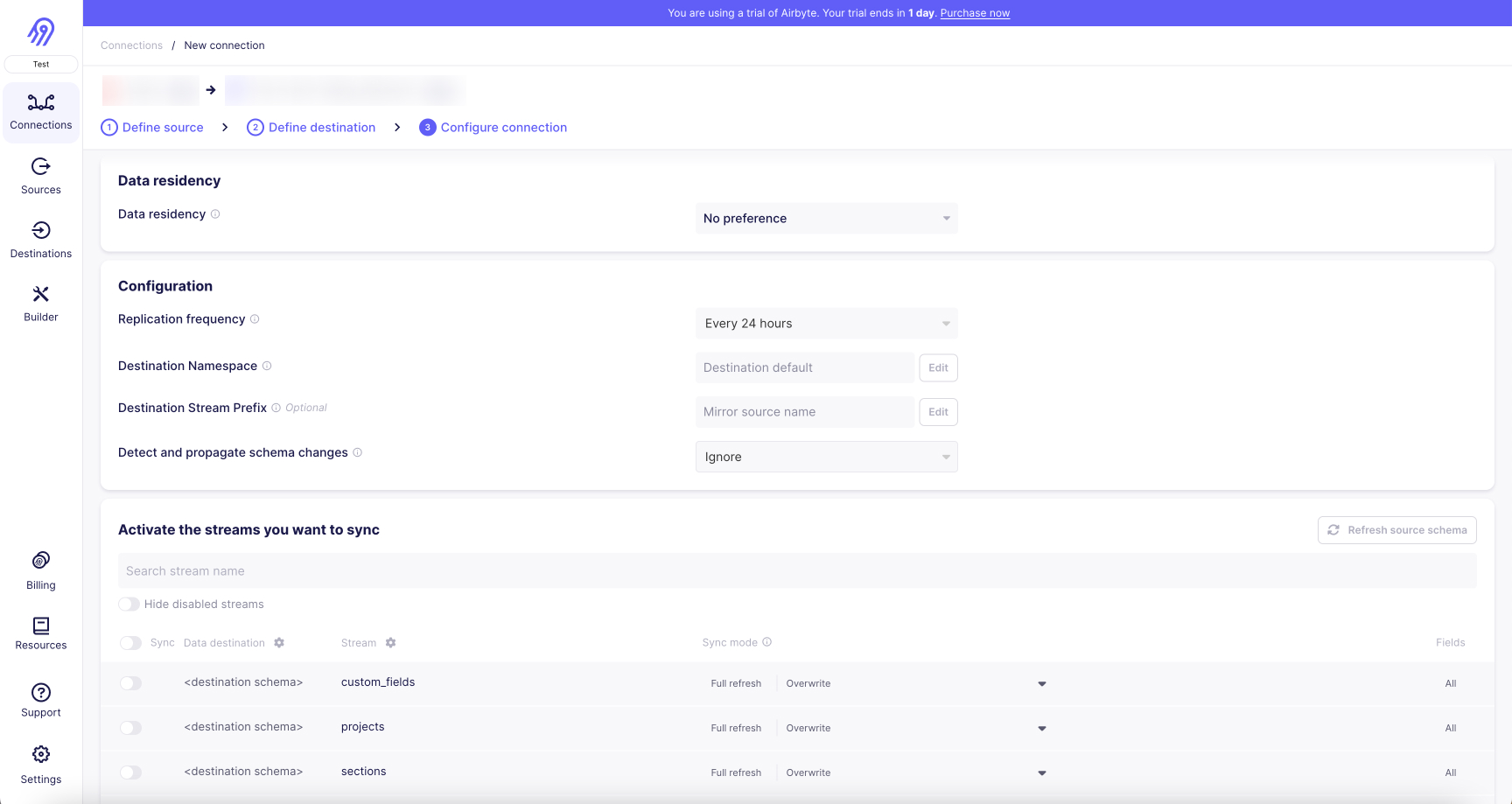
Once you've successfully connected CSV File as a data source and Cassandra as a destination in Airbyte, you can set up a data pipeline between them with the following steps:
- Create a new connection: On the Airbyte dashboard, navigate to the 'Connections' tab and click the '+ New Connection' button.
- Choose your source: Select CSV File from the dropdown list of your configured sources.
- Select your destination: Choose Cassandra from the dropdown list of your configured destinations.
- Configure your sync: Define the frequency of your data syncs based on your business needs. Airbyte allows both manual and automatic scheduling for your data refreshes.
- Select the data to sync: Choose the specific CSV File objects you want to import data from towards Cassandra. You can sync all data or select specific tables and fields.
- Select the sync mode for your streams: Choose between full refreshes or incremental syncs (with deduplication if you want), and this for all streams or at the stream level. Incremental is only available for streams that have a primary cursor.
- Test your connection: Click the 'Test Connection' button to make sure that your setup works. If the connection test is successful, save your configuration.
- Start the sync: If the test passes, click 'Set Up Connection'. Airbyte will start moving data from CSV File to Cassandra according to your settings.
Remember, Airbyte keeps your data in sync at the frequency you determine, ensuring your Cassandra data warehouse is always up-to-date with your CSV File data.
Use Cases to transfer your CSV File data to Cassandra
Integrating data from CSV File to Cassandra provides several benefits. Here are a few use cases:
- Advanced Analytics: Cassandra’s powerful data processing capabilities enable you to perform complex queries and data analysis on your CSV File data, extracting insights that wouldn't be possible within CSV File alone.
- Data Consolidation: If you're using multiple other sources along with CSV File, syncing to Cassandra allows you to centralize your data for a holistic view of your operations, and to set up a change data capture process so you never have any discrepancies in your data again.
- Historical Data Analysis: CSV File has limits on historical data. Syncing data to Cassandra allows for long-term data retention and analysis of historical trends over time.
- Data Security and Compliance: Cassandra provides robust data security features. Syncing CSV File data to Cassandra ensures your data is secured and allows for advanced data governance and compliance management.
- Scalability: Cassandra can handle large volumes of data without affecting performance, providing an ideal solution for growing businesses with expanding CSV File data.
- Data Science and Machine Learning: By having CSV File data in Cassandra, you can apply machine learning models to your data for predictive analytics, customer segmentation, and more.
- Reporting and Visualization: While CSV File provides reporting tools, data visualization tools like Tableau, PowerBI, Looker (Google Data Studio) can connect to Cassandra, providing more advanced business intelligence options. If you have a CSV File table that needs to be converted to a Cassandra table, Airbyte can do that automatically.
Wrapping Up
To summarize, this tutorial has shown you how to:
- Configure a CSV File account as an Airbyte data source connector.
- Configure Cassandra as a data destination connector.
- Create an Airbyte data pipeline that will automatically be moving data directly from CSV File to Cassandra after you set a schedule
With Airbyte, creating data pipelines take minutes, and the data integration possibilities are endless. Airbyte supports the largest catalog of API tools, databases, and files, among other sources. Airbyte's connectors are open-source, so you can add any custom objects to the connector, or even build a new connector from scratch without any local dev environment or any data engineer within 10 minutes with the no-code connector builder.
We look forward to seeing you make use of it! We invite you to join the conversation on our community Slack Channel, or sign up for our newsletter. You should also check out other Airbyte tutorials, and Airbyte’s content hub!
What should you do next?
Hope you enjoyed the reading. Here are the 3 ways we can help you in your data journey:

Easily address your data movement needs with Airbyte Cloud
Take the first step towards extensible data movement infrastructure that will give a ton of time back to your data team.
Get started with Airbyte for free
Talk to a data infrastructure expert
Get a free consultation with an Airbyte expert to significantly improve your data movement infrastructure.
Talk to sales
Improve your data infrastructure knowledge
Subscribe to our monthly newsletter and get the community’s new enlightening content along with Airbyte’s progress in their mission to solve data integration once and for all.
Subscribe to newsletterRelated Syncs with CSV File
What should you do next?
Hope you enjoyed the reading. Here are the 3 ways we can help you in your data journey:
Easily address your data movement needs with Airbyte Cloud
Take the first step towards extensible data movement infrastructure that will give a ton of time back to your data team.
Get started with Airbyte for freeTalk to a data infrastructure expert
Get a free consultation with an Airbyte expert to significantly improve your data movement infrastructure.
Talk to salesImprove your data infrastructure knowledge
Subscribe to our monthly newsletter and get the community’s new enlightening content along with Airbyte’s progress in their mission to solve data integration once and for all.
Subscribe to newsletterRelated Syncs with CSV File
.webp)
