

Top companies trust Airbyte to centralize their Data










Ship more quickly with the only solution that fits ALL your needs.
As your tools and edge cases grow, you deserve an extensible and open ELT solution that eliminates the time you spend on building and maintaining data pipelines
Leverage the largest catalog of connectors
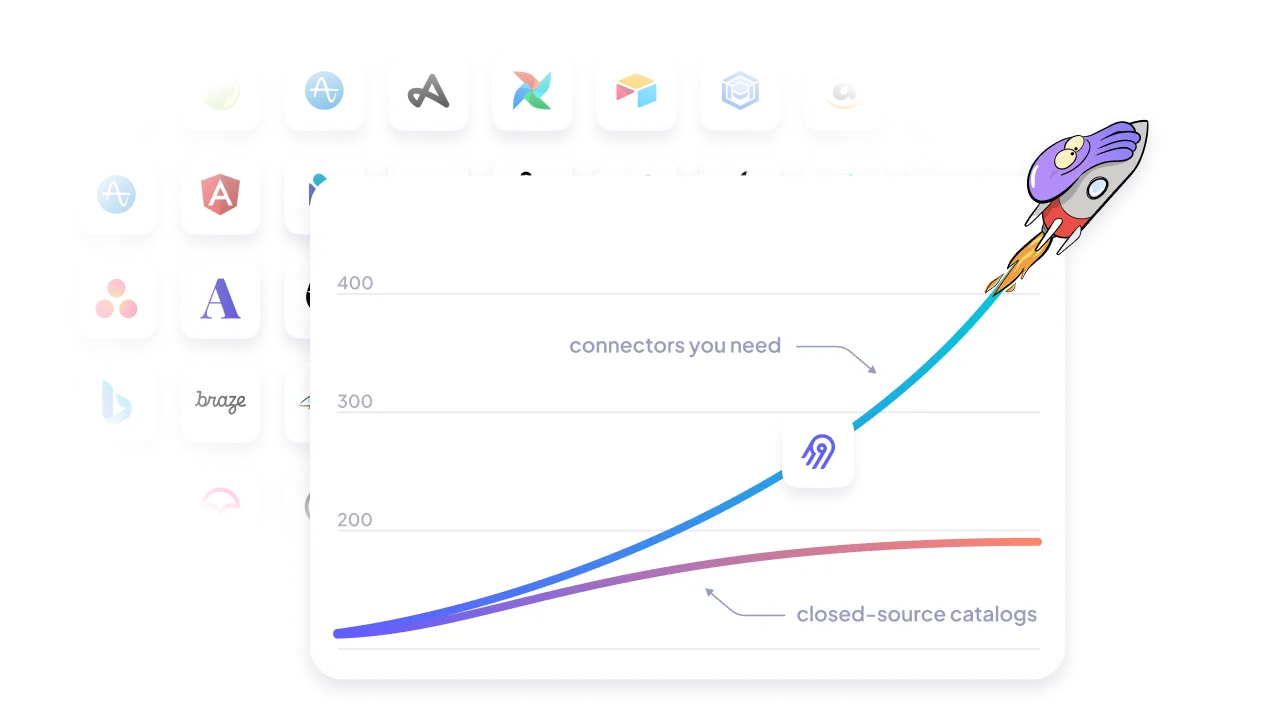
Cover your custom needs with our extensibility

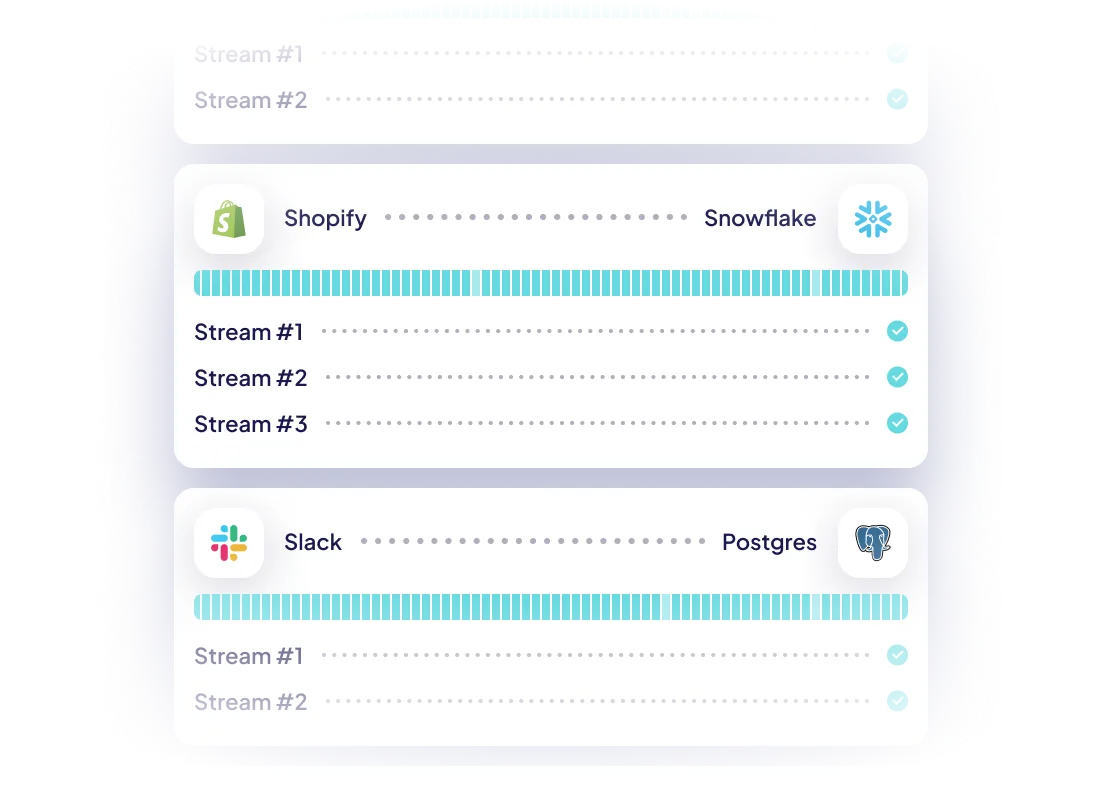
Free your time from maintaining connectors, with automation
- Automated schema change handling, data normalization and more
- Automated data transformation orchestration with our dbt integration
- Automated workflow with our Airflow, Dagster and Prefect integration

Reliability at every level



Airbyte Open Source

Airbyte Cloud

Airbyte Enterprise
Why choose Airbyte as the backbone of your data infrastructure?
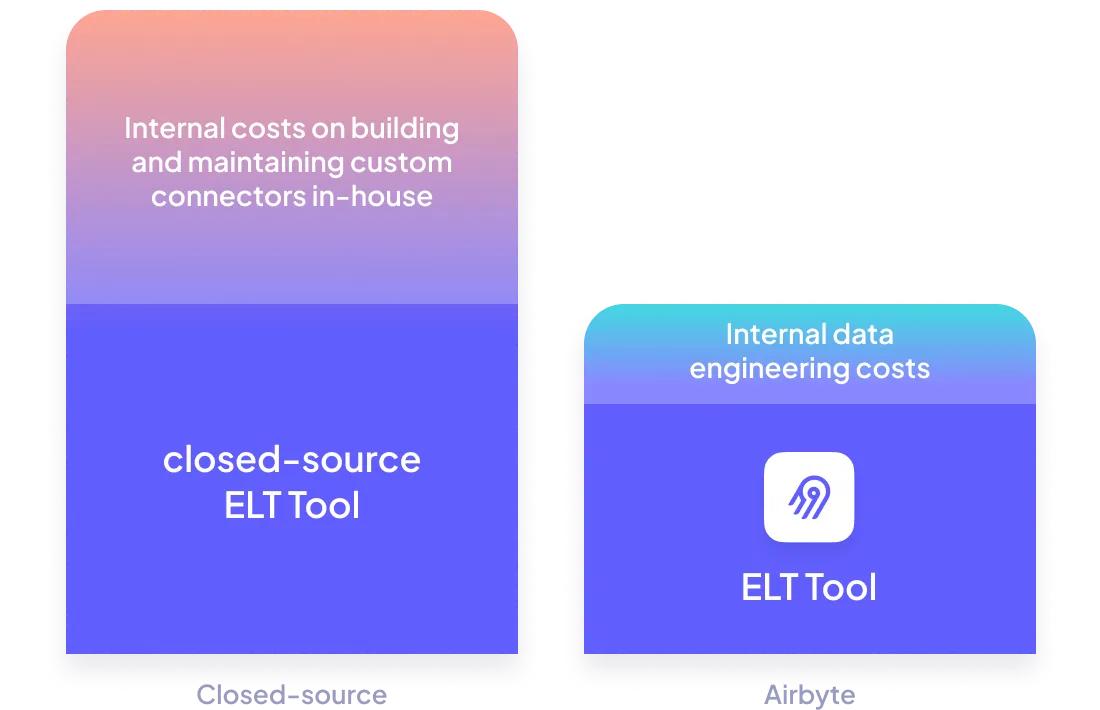
Keep your data engineering costs in check
Get Airbyte hosted where you need it to be
- Airbyte Cloud: Have it hosted by us, with all the security you need (SOC2, ISO, GDPR, HIPAA Conduit).
- Airbyte Enterprise: Have it hosted within your own infrastructure, so your data and secrets never leave it.

White-glove enterprise-level support
Including for your Airbyte Open Source instance with our premium support.


Fnatic, based out of London, is the world's leading esports organization, with a winning legacy of 16 years and counting in over 28 different titles, generating over 13m USD in prize money. Fnatic has an engaged follower base of 14m across their social media platforms and hundreds of millions of people watch their teams compete in League of Legends, CS:GO, Dota 2, Rainbow Six Siege, and many more titles every year.
Ready to get started?
FAQs
What is ETL?
ETL, an acronym for Extract, Transform, Load, is a vital data integration process. It involves extracting data from diverse sources, transforming it into a usable format, and loading it into a database, data warehouse or data lake. This process enables meaningful data analysis, enhancing business intelligence.
The Times Developer Network is our API clearinghouse and community. You need to read the API documentation and browse the application gallery to get the latest news about the New York Times API. If you do not agree to any of the terms below or the NYT Terms of Service, NYT does not grant you a license to use the NYT API. In the event of any inconsistency between these Terms of Use and the Terms of Service, these Terms of Use control.
MariaDB Columnstore is a powerful tool designed for big data analytics and business intelligence. It is a columnar storage engine that allows users to store and analyze large amounts of data in real-time. The tool is built on top of the MariaDB database management system and is designed to handle complex queries and data processing tasks. MariaDB Columnstore is designed to provide high performance and scalability, making it ideal for organizations that need to process large amounts of data quickly. It is also highly flexible, allowing users to customize the tool to meet their specific needs. One of the key features of MariaDB Columnstore is its ability to handle both structured and unstructured data. This means that users can analyze data from a wide range of sources, including social media, web logs, and other unstructured data sources. Overall, MariaDB Columnstore is a powerful tool that can help organizations make better decisions by providing them with the insights they need to succeed. Whether you are looking to analyze customer data, track sales trends, or monitor website traffic, MariaDB Columnstore can help you get the job done quickly and efficiently.
The New York Times API provides access to a wide range of data categories, including:
1. Articles: Full-text articles from the New York Times, including news, opinion, and feature pieces.
2. Multimedia: Images, videos, and other multimedia content from the New York Times.
3. Best Sellers: Lists of best-selling books, both fiction and non-fiction, as compiled by the New York Times.
4. Movie Reviews: Reviews of movies from the New York Times, including ratings and summaries.
5. TimesTags: A comprehensive list of tags used by the New York Times to categorize articles and other content.
6. Times Newswire: A real-time feed of breaking news stories from the New York Times.
7. Top Stories: A list of the most popular articles on the New York Times website, updated in real-time.
8. Archive: Access to the New York Times archive, including articles dating back to 1851.
9. Times Insider: Exclusive content from the New York Times, including behind-the-scenes stories and interviews with journalists.
Overall, the New York Times API provides a wealth of data for developers and researchers interested in exploring the content and history of one of the world's most respected news organizations.
What is ELT?
ELT, standing for Extract, Load, Transform, is a modern take on the traditional ETL data integration process. In ELT, data is first extracted from various sources, loaded directly into a data warehouse, and then transformed. This approach enhances data processing speed, analytical flexibility and autonomy.
Difference between ETL and ELT?
ETL and ELT are critical data integration strategies with key differences. ETL (Extract, Transform, Load) transforms data before loading, ideal for structured data. In contrast, ELT (Extract, Load, Transform) loads data before transformation, perfect for processing large, diverse data sets in modern data warehouses. ELT is becoming the new standard as it offers a lot more flexibility and autonomy to data analysts.


















